
Gradient Accumulationを使えば、サイズの大きいモデルでもバッチサイズを確保しながら学習できます。
考え方としては、設定できるバッチサイズの最大が2だとしても、acc_step = 8にすると実質2×8=16のバッチサイズにできるという感じです。
Gradient Accumulationの使い方
データセット
import torchvision
train = torchvision.datasets.CIFAR10(
root = "data",
train = True,
download = True,
transform = torchvision.transforms.ToTensor()
)
valid = torchvision.datasets.CIFAR10(
root = "data",
train = False,
download = True,
transform = torchvision.transforms.ToTensor()
)CIFAR10で画像分類をします。
trainが学習用で、validが検証用です。
データセット, モデル定義
import torch
import torch.nn as nn
from torch.utils.data import Dataset, DataLoader
# !pip install -Uqqq timm
import timm
from tqdm import tqdm
import albumentations as A
import matplotlib.pyplot as plt
from timm.utils import AverageMeter
class CustomData(Dataset):
def __init__(self, data, transform):
self.data = data
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img, lbl = self.data[idx]
img = img.permute(1, 2, 0).numpy()
if self.transform is not None:
img = self.transform(image = img)["image"]
img = torch.from_numpy(img).permute(2, 0, 1)
return img, lbl先程取得したデータを取り出すようにしています。
idx=0が最初のデータで、train[idx] = 画像, ラベルみたいに取り出せます。
model = timm.create_model("resnet34d", pretrained = True, num_classes = 10).cuda()
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()モデルはresnet34dにしておきます。後ほど大きなモデルにしてみましょう。
ちなみに使っているGPUはGoogle ColabのT4です。
Gradient Accumulationなしで学習
batch_size = 32
train_ds = CustomData(train, A.Compose([A.Flip(), A.RandomRotate90()]))
train_dl = DataLoader(train_ds, batch_size = batch_size, shuffle = True, pin_memory = True)
valid_ds = CustomData(valid, None)
valid_dl = DataLoader(valid_ds, batch_size = batch_size, shuffle = False, pin_memory = True)
results = {"train": [], "valid": []}
for epoch in range(10):
model.train()
train_loss = AverageMeter()
for x, y in tqdm(train_dl):
x = x.cuda()
y = y.cuda()
logits = model(x)
loss = criterion(logits, y)
train_loss.update(val = loss.item(), n = len(y))
loss.backward()
optimizer.step()
optimizer.zero_grad()
valid_loss = AverageMeter()
for x, y in tqdm(valid_dl):
x = x.cuda()
y = y.cuda()
with torch.no_grad():
logits = model(x)
valid_loss.update(val = loss.item(), n = len(y))
print(train_loss.avg)
print(valid_loss.avg)
results["train"].append(train_loss.avg)
results["valid"].append(valid_loss.avg)
plt.plot(results["train"])
plt.plot(results["valid"])
plt.show()バッチサイズは32です。アウトプットは以下のとおり。
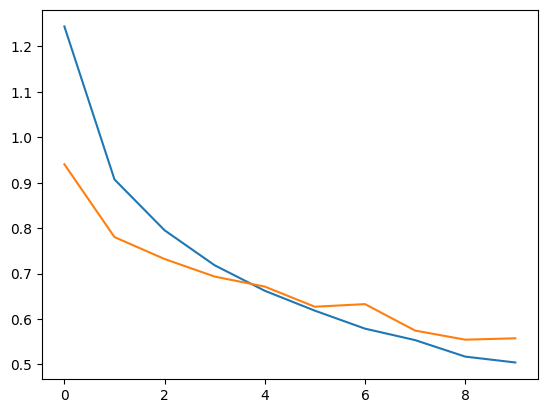
正解率は80%くらいになります。
Gradient Accumulationありで学習
acc_step = 4
batch_size = 8
train_ds = CustomData(train, A.Compose([A.Flip(), A.RandomRotate90()]))
train_dl = DataLoader(train_ds, batch_size = batch_size, shuffle = True, pin_memory = True)
valid_ds = CustomData(valid, None)
valid_dl = DataLoader(valid_ds, batch_size = batch_size, shuffle = False, pin_memory = True)
model = timm.create_model("resnet34d", pretrained = True, num_classes = 10).cuda()
optimizer = torch.optim.Adam(model.parameters())
criterion = nn.CrossEntropyLoss()
results = {"train": [], "valid": []}
for epoch in range(10):
model.train()
train_loss = AverageMeter()
for i, (x, y) in enumerate(tqdm(train_dl)):
x = x.cuda()
y = y.cuda()
logits = model(x)
loss = criterion(logits, y)
train_loss.update(val = loss.item(), n = len(y))
loss /= acc_step
loss.backward()
if (i + 1) % acc_step == 0:
optimizer.step()
optimizer.zero_grad()
valid_loss = AverageMeter()
for x, y in tqdm(valid_dl):
x = x.cuda()
y = y.cuda()
with torch.no_grad():
logits = model(x)
valid_loss.update(val = loss.item(), n = len(y))
print(train_loss.avg)
print(valid_loss.avg)
results["train"].append(train_loss.avg)
results["valid"].append(valid_loss.avg)
plt.plot(results["train"])
plt.plot(results["valid"])
plt.show()acc_stepが勾配を溜め込むステップ数です。
batch_size x acc_step = 4 x 8 = 32が実質のバッチサイズになります。
変更点は、まずlossをacc_stepで割ること。あとは1エポック内のステップ数をiとして(i + 1)%acc_step=0のときに重みを更新することです。
結果は以下のとおり。
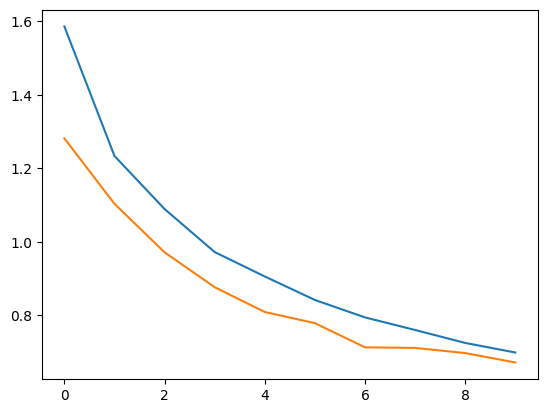
結果はちょっと変わりますが、問題なく学習できていますね。
まとめ
Gradient Accumulationの解説をしました。自然言語処理だとモデルが大きすぎてバッチサイズを確保しにくいので、この方法で学習の安定性を確保できそうですね。

コメント