
TabNetで機械学習モデルを作る方法を解説します。
Kaggleでもちょいちょい見かける、表形式データで使えるモデルです。
回帰モデル
データセット
import pandas as pd
from sklearn.datasets import load_diabetes
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
データは”load_diabetes”を使います。
“age” ~ “s6″までの特徴量から”target”を予測しましょう。
データ分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.1, random_state = 0)
print(train.shape, test.shape)
features = [c for c in df.columns if c != "target"]
print(features)
# ========== output ==========
# (397, 11) (45, 11)
# ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']“train_test_split”で学習用データと検証用データとに分割しました。
標準化
from sklearn.preprocessing import StandardScaler
print(train["age"].mean(), train["age"].std())
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
print("\n=>", train["age"].mean(), train["age"].std())
# ========== output ==========
# 0.00030482651954818986 0.048139568948158046
# => 0.0 1.0012618301549563TabNetはニューラルネット系のモデルなので、標準化しておきましょう。
#学習用データ
X_train = train[features].values
y_train = train["target"].values.reshape(-1, 1)
#検証用データ
X_test = test[features].values
y_test = test["target"].values.reshape(-1, 1)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# (397, 10) (397,)
# (45, 10) (45,)モデルに入れる特徴量をX、答えをyにしました。
学習と検証
#!pip install -q pytorch-tabnet
import torch
from pytorch_tabnet.tab_model import TabNetRegressor“pytorch-tabnet”をインストールし、インポートしましょう。
PARAMS = dict(
seed = 0, # 乱数固定
optimizer_params = dict(lr = 1e-2), # 学習率設定
verbose = 10, # ログ出力頻度
)
# モデル作成
model = TabNetRegressor(**PARAMS)
# 学習と検証
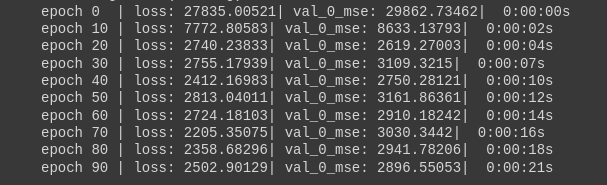
model.fit(
X_train, y_train,
eval_set = [(X_test, y_test)],
batch_size = 32, # データを小出しするサイズ
max_epochs = 100, # 学習回数
patience = 0, # early_stoppping(0は無し)
)
パラメータを設定して、“TabNetRegressor”に渡しましょう。
fitで学習を開始します。
デフォルトの学習率が1e-3でうまく進まなかったので1e-2にしました。
また”patience”がGBDT系で言う”early_stopping”で、
デフォルトで設定されているので0にしています。
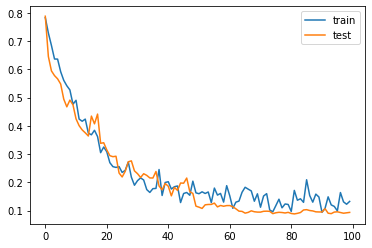
実行してみると徐々にlossが下がっていることがわかりますね。
import matplotlib.pyplot as plt
plt.plot(model.history["loss"], label = "train")
plt.plot(model.history["val_0_mse"], label = "test")
plt.show()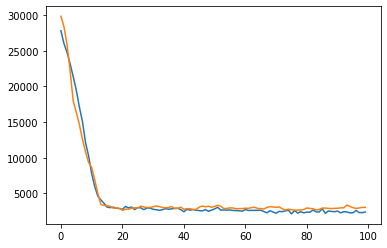
“history”に学習ログが保存されているので、簡単に経過を見ることができます。
ちょっと過学習していますね。
予測
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
preds = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test, preds)))
print(r2_score(y_test, preds))
# ========== output ==========
# 55.06539557534071
# 0.3736876916632369“predict”で予測できます。R2スコアが0.37でした。
パラメータ変更
PARAMS = dict(
seed = 0,
optimizer_params = dict(lr = 1e-2),
# 学習率を徐々に小さくする
scheduler_fn = torch.optim.lr_scheduler.CosineAnnealingLR,
# 学習回数と同じ値にする
scheduler_params = dict(T_max = 100),
verbose = 10,
)
model = TabNetRegressor(**PARAMS)
model.fit(
X_train, y_train,
eval_set = [(X_test, y_test)],
batch_size = 32,
max_epochs = 100,
patience = 0,
)
plt.plot(model.history["loss"], label = "train")
plt.plot(model.history["val_0_mse"], label = "test")
plt.show()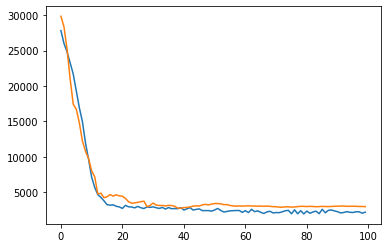
学習率を徐々に落とすことで、lossが極小値にたどり着きやすくしています。
“CosineAnnealingLR”はよく使われる手法です。
cosine関数に従って徐々に学習率が小さくなります。
学習率の変更は1epochごとに行われるので、”T_max”を学習回数(max_epochs)に合わせましょう。
preds = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test, preds)))
print(r2_score(y_test, preds))
# ========== output ==========
# 54.432142993959175
# 0.3880100569209015精度を計算するとR2スコアが0.388に伸び、RMSEも下がっていますね。
二値分類モデル
データセット
import pandas as pd
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df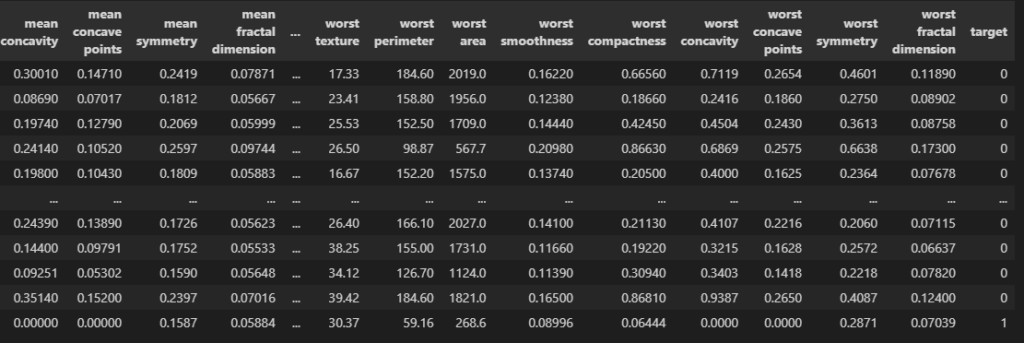
30列の特徴量から”target”が0か1かを予測しましょう。
前処理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
train, test = train_test_split(df, test_size = 0.1, random_state = 0, stratify = df["target"])
print(train["target"].mean())
print(test["target"].mean())
features = [c for c in df.columns if c != "target"]
print("num features:", len(features))
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
#学習用データ
X_train = train[features].values
y_train = train["target"].values
#検証用データ
X_test = test[features].values
y_test = test["target"].values
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# 0.626953125
# 0.631578947368421
# num features: 30
# (512, 30) (512, 1)
# (57, 30) (57, 1)データ分割、標準化、特徴量と答えとに分ける処理をしました。
“stratify”に”target”を指定すると、ラベルの分布を保ちながら分割してくれます。
学習と検証
#!pip install -q pytorch-tabnet
import torch
from pytorch_tabnet.tab_model import TabNetClassifier
PARAMS = dict(
seed = 0, # 乱数固定
optimizer_params = dict(lr = 1e-3), # 学習率設定
verbose = 10, # ログ出力頻度
)
# モデル作成
model = TabNetClassifier(**PARAMS)
# 学習と検証
model.fit(
X_train, y_train,
eval_set = [(X_test, y_test)],
batch_size = 32, # データを小出しするサイズ
max_epochs = 100, # 学習回数
patience = 0, # early_stoppping(0は無し)
eval_metric = ["logloss"], # 評価指標
)分類モデルの場合は、“TabNetClassifier”を使いましょう。
“eval_metric”で評価指標を設定しています。デフォルトは”AUC”です。
予測
from sklearn.metrics import accuracy_score
preds = model.predict(X_test).round()
print(accuracy_score(y_test, preds))
# ========== output ==========
# 0.9473684210526315“predict”で予測すると、ラベル1に該当する確率を出力します。
なので閾値をもって確率をラベルに変更しましょう。今回はシンプルに四捨五入しました。
正解率は94.7%ですね。
他クラス分類モデル
データセット
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df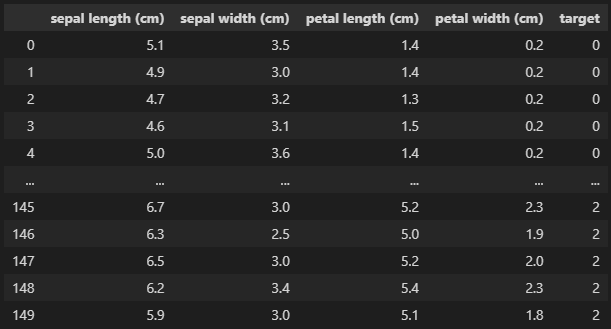
“sepal length” ~ “petal width”までの4つの特徴量から”target”を予測します。
“target”は0 ~ 2まで3種類あります。
前処理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
train, test = train_test_split(df, test_size = 0.1, random_state = 0, stratify = df["target"])
features = [c for c in df.columns if c != "target"]
print(features)
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
#学習用データ
X_train = train[features].values
y_train = train["target"].values
#検証用データ
X_test = test[features].values
y_test = test["target"].values
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
# (135, 4) (135,)
# (15, 4) (15,)これまでと同じように前処理をしました。
学習と検証
#!pip install -q pytorch-tabnet
import torch
from pytorch_tabnet.tab_model import TabNetClassifier
import matplotlib.pyplot as plt
PARAMS = dict(
seed = 0, # 乱数固定
optimizer_params = dict(lr = 2e-3), # 学習率設定
verbose = 10, # ログ出力頻度
)
# モデル作成
model = TabNetClassifier(**PARAMS)
# 学習と検証
model.fit(
X_train, y_train,
eval_set = [(X_test, y_test)],
batch_size = 32, # データを小出しするサイズ
max_epochs = 100, # 学習回数
patience = 0, # early_stoppping(0は無し)
eval_metric = ["logloss"], # 評価指標
)
plt.plot(model.history["loss"], label = "train")
plt.plot(model.history["val_0_logloss"], label = "test")
plt.legend()
plt.show()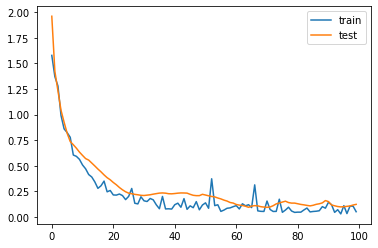
他クラス分類でも”TabNetClassifier”を使います。
評価指標はデフォルトで正解率になるので、”logloss”にしました。
予測
from sklearn.metrics import accuracy_score
probs = model.predict_proba(X_test)
print(probs.shape)
preds = model.predict(X_test)
print(accuracy_score(y_test, preds))
# ========== output ==========
# (15, 3)
# 0.9333333333333333“predict_proba”を使うと各ラベルに該当する確率を出力します。
“predict”は予測ラベル(今回なら0, 1, 2)を直接予測します。
正解率を計算すると93.3%でした。
まとめ
今回はTabNetの使い方を解説しました。
GBDT系モデルとのアンサンブルに使われたりするので、扱えるようになっておきたいですね。


コメント