
機械学習で画像分類をやってみたいけど、
初心者すぎてなにしたらいいかわからない。。。
という方は、手書き数字のデータを使って分類してみましょう。
すごく簡単なないようなので、初心者でも取り組みやすいです。
Python実行環境がない人はGoogle Colabolatoryを使いましょう。
>>Google Colaboratoryの使い方
データセット
データはscikit-learnに最初から入っているものを使います。
load_digits
from sklearn.datasets import load_digits
import pandas as pd
data = load_digits()
df = pd.DataFrame(data = data["data"], columns = data["feature_names"])
df["target"] = data["target"]
print(df.shape)
df.head()
# ========== outputs ==========
# (1797, 65)
scikit-learnにある”load_digits”を読み込みましょう。
pixel_0_0~pixel_7_7といったデータが入っていますね。
print(df["target"].value_counts())
# ========== outputs ==========
# 3 183
# 1 182
# 5 182
# ...
# 8 174targetが予測する列で、0~9までの10種類あります。
これは要するに、pixel_0_0~pixel_7_7のデータからtargetの数値を予測しましょうということです。
画像可視化
feature_cols = [c for c in df.columns if c != "target"]
print(feature_cols[:5])
print(df[feature_cols].values[0].shape)
# ========== outputs ==========
# ['pixel_0_0', 'pixel_0_1', 'pixel_0_2', 'pixel_0_3', 'pixel_0_4']
# (64,)画像サイズは8 x 8です。
各マスの値が”pixel_x_y”の形式で入っています。
import matplotlib.pyplot as plt
plt.imshow(df[feature_cols].values[0].reshape(8, 8))
plt.show()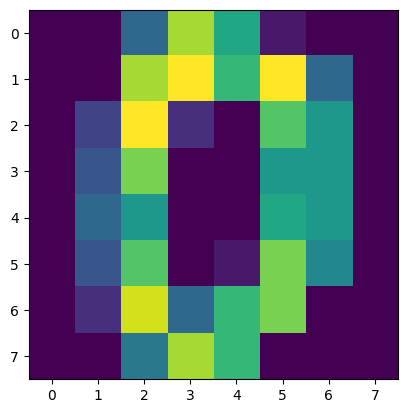
このように64列の特徴量を8 x 8に直すと画像として確認できます。
これは0で、その行のtargetも0です。
import random
ids = random.sample(range(len(df)), 9)
plt.figure()
for i in range(9):
_id = ids[i]
plt.subplot(3, 3, i + 1)
plt.imshow(df[feature_cols].values[_id].reshape(8, 8))
plt.title(df["target"].values[_id])
plt.tight_layout()
plt.show()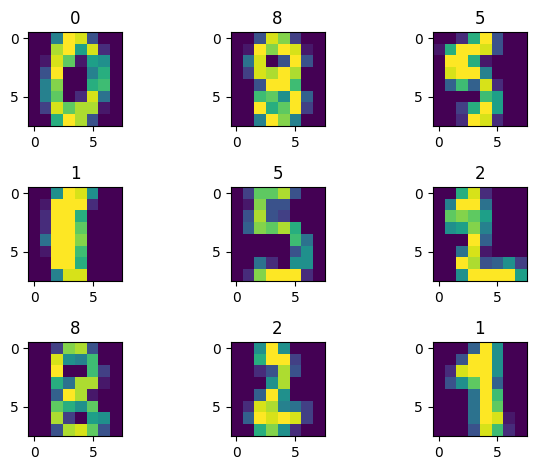
こんな感じで画像は粗いですが、なんとなく数値が読み取れるはずです。
これらの画像からラベルの数値を当てることができたら成功ですね。
データ分割
学習データと検証データに分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, stratify = df["target"], test_size = 0.1, random_state = 0)
print(train.shape, test.shape)
# ========== outputs ==========
# (1617, 65) (180, 65)基本的にモデルの性能を確認するときは、検証データを使います。
要するに、学習済みモデルがまだ見たことないデータで精度を確かめましょう。
>>交差検証でよく使うデータ分割法
特徴量と目的変数に分割
X_train = train[feature_cols]
y_train = train["target"]
X_test = test[feature_cols]
y_test = test["target"]
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== outputs ==========
# (1617, 64) (1617,)
# (180, 64) (180,)Xをモデルに入れる特徴量、yを予測したい目的変数にしました。
特徴量は画像の8 x 8ピクセルなので64列です。
モデル作成:LightGBM
完全初心者の人はLightGBMを使ってみましょう。
使い方について詳しくは以下の記事で解説しています。
>>LightGBMの使い方
学習と検証
# インポート
import lightgbm as lgbm
# パラメータ設定
params = {
"objective": "multiclass", # 他クラス分類
"num_class": 10, # クラス数
"verbosity": -1,
}
# データセット作成
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# ログ保存用の変数
history = {}
# 学習開始
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
callbacks = [lgbm.callback.record_evaluation(history)], # ログを保存
)
# ログ可視化
plt.plot(history["training"]["multi_logloss"], label = "train")
plt.plot(history["valid_1"]["multi_logloss"], label = "valid")
plt.legend()
plt.show()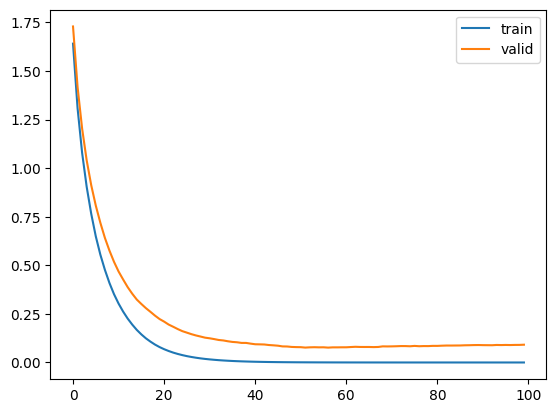
重要なところはパラメータ設定で、num_classを予測する種類数に合わせましょう。
今回は0~9なので10種類です。
historyには学習過程を保存しています。
可視化すると、徐々に誤差が下がっていることがわかりますね。
予測
predictで予測できます。
モデルが答えを知らない検証データで予測しましょう。
preds = model.predict(X_test)
print(preds.shape)
print(preds[0, :])
# ========== outputs ==========
# (180, 10)
# [4.00971598e-08 5.62495980e-08 5.19971996e-08 1.03801594e-07
# 1.07763125e-07 8.64257186e-08 9.99999361e-01 4.66541723e-08
# 1.11671590e-07 3.44739145e-08]予測結果は10列になっていて、それぞれが各数字に該当する確率です。
1個目のデータを見ると、わかりづらいですが6になる確率が最も高いです。
精度検証
from sklearn.metrics import accuracy_score
pred_labels = preds.argmax(axis = 1)
accuracy_score(y_test, pred_labels)
# ========== outputs ==========
# 0.9722222222222222argmaxを使って列方向の最大値の番号を取ります。
要するに最も確率の高い列番号を予測したラベル(数字)としました。
正解率を計算すると97.2%でした。
完全に初心者の方で難しいことをしたくないなら、ここまででOKです!
モデル作成:ニューラルネット
もっとカッコ良さげなモデルを作りたい。。。
と思っている方は、ニューラルネットに挑戦しましょう。
主な作り方は以下の記事で解説しています。
>>pytorchとtimmで画像分類モデルを作る方法
Dataset
import torch
from torch.utils.data import Dataset, DataLoader
class CustomData(Dataset):
def __init__(self, data, feature_cols):
self.data = data
self.feature_cols = feature_cols
def __len__(self):
return len(self.data)
def __getitem__(self, idx): # idxが行番号になる
# 特徴量を取り出す
features = self.data[self.feature_cols].values[idx].reshape(8, 8)
features = torch.from_numpy(features).unsqueeze(0).float()
# 答えの数字を取り出す
target = self.data["target"].values[idx]
target = torch.tensor(target, dtype = torch.long)
return features, targetDatasetを定義します。一見難しそうに見えますが、やっていることは単純です。
idxが行番号で、それに該当する特徴量(features)と目的変数(target)を出しているだけです。
ds = CustomData(train, feature_cols)
print(ds[0][0].shape)
print(ds[0][1])
# ========== outputs ==========
# torch.Size([1, 8, 8])
# tensor(7)こんな感じで、最初はinitで使われるデータと列名を入れます。
ds[0]でidx = 0として動くので、0行目のデータを取り出します。
特徴量は画像として使いたいので、(1チャネル, 8, 8)としています。
DataLoader
dl = DataLoader(ds, batch_size = 4)
b = next(iter(dl))
print(b[0].shape)
print(b[1].shape)
# ========== outputs ==========
# torch.Size([4, 1, 8, 8])
# torch.Size([4])DataLoaderは小さなデータの塊(バッチ)ごとにデータを出してくれます。
batch_size = 4にすると1度に4行ずつ取り出せます。
モデル定義
import timm
model = timm.create_model("resnet18d", pretrained = True, in_chans = 1, num_classes = 10)timmを使うと簡単に優秀なモデルを使うことができます。
resnet18dは計算が軽くてCPUでも使えます。他にはEfficientNetB0がおすすめです。
学習と検証
import torch.nn as nn
# 最適化手法
optimizer = torch.optim.Adam(model.parameters())
# 損失関数
criterion = nn.CrossEntropyLoss()
# Dataset, DataLoader
train_ds = CustomData(train, feature_cols)
test_ds = CustomData(test, feature_cols)
train_dl = DataLoader(train_ds, batch_size = 32, shuffle = True, drop_last = True)
test_dl = DataLoader(test_ds, batch_size = 32 * 2, shuffle = False, drop_last = False)最適化手法と損失関数を定義します。
最適化手法は無難なAdam、損失関数は他クラス分類なのでCrossEntropyLossにしました。
for epoch in range(10): # 学習回数
print("\nEpoch:", epoch)
# 学習
model.train()
train_loss = 0
for batch in train_dl:
# 勾配リセット
optimizer.zero_grad()
# データ取り出し, 予測
image = batch[0]
label = batch[1]
logits = model(image)
# 誤差計算
loss = criterion(logits, label)
# 誤差伝播
loss.backward()
# パラメータ更新
optimizer.step()
# 誤差記録(なくてもいい)
train_loss += loss.item()
train_loss /= len(train_dl)
print(train_loss)
# 検証
model.eval()
test_loss = 0
with torch.no_grad():
for batch in test_dl:
image = batch[0]
label = batch[1]
logits = model(image)
loss = criterion(logits, label)
test_loss += loss.item()
test_loss /= len(test_dl)
print(test_loss)学習と検証を10回繰り返しました。徐々にlossが下がっていたらOKです。
予測
import numpy as np
model.eval()
preds = []
with torch.no_grad():
for batch in test_dl:
image = batch[0]
logits = model(image)
preds.append(nn.Softmax(dim = -1)(logits).numpy())
preds = np.concatenate(preds, axis = 0)
print(preds.shape)
# ========== outputs ==========
# (180, 10)検証の時と同じようにして予測していきます。
出力の列方向に対してSoftmaxを使って、各ラベル(数字)に該当する確率にしましょう。
concatenateで出力を行方向にくっつけることができます。
最終的にサイズは(行数, ラベルの種類数)になるはずです。
精度検証
accuracy_score(y_test, preds.argmax(axis = 1))
# ========== outputs ==========
# 0.961111111111111196.1%でした。LightGBMよりも低かったです。
画像サイズが小さいので、あまり凝ったことをしない方が良かったかもしれませんね。
まとめ
今回は手書き数字の画像を分類する方法について解説しました。
サイズが8 x 8と小さく取り扱いやすいので、初心者の勉強におすすめです。

コメント