
LightGBMとtf-idfを使った簡単な分類からやってみましょう。
最近の主流はBERTですが、こちらは計算が重くGPUが必要なので、
とりあえず文章分類を勉強してみたいなら今回の内容がおすすめです。
【関連記事】BERTで文章分類をする方法
データセット
勉強に使えるデータセットを持っていない人は、scikit-learnに入っているものを使いましょう。
以下のコードでダウンロードします。
import pandas as pd
from sklearn.datasets import fetch_20newsgroups
train_data = fetch_20newsgroups(subset = 'train')
test_data = fetch_20newsgroups(subset = 'test')
train = pd.DataFrame({"text" : train_data["data"], "target" : train_data["target"]})
test = pd.DataFrame({"text" : test_data["data"], "target" : test_data["target"]})
train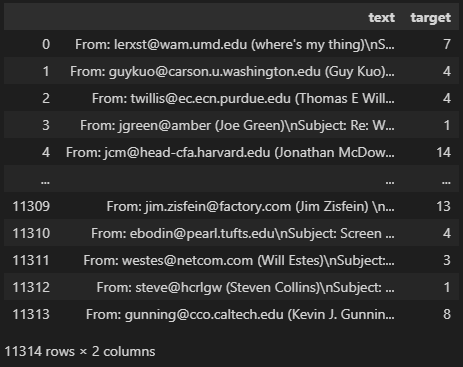
fetch_20newsgroupsというデータセットを使います。
以下のように文章のデータが入っています。
print(train["text"].values[0])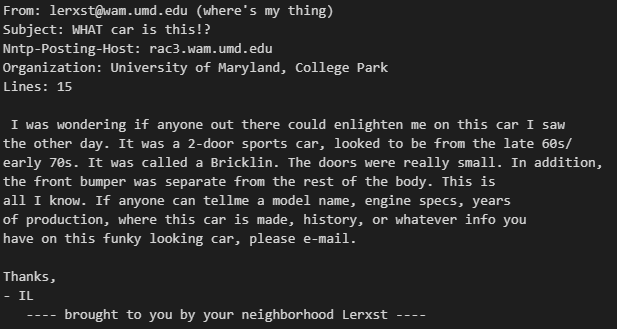
各文章は、その内容によってラベル0~19までの20種類にわけられています。
print(sorted(train["target"].unique()))
print(sorted(test["target"].unique()))
# ========== output ==========
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]
# [0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19]なので今回の目標は、各文章がどの番号(種類)に該当するかを分類することです。
tf-idf
tf-idfとは、ある文章において重要な単語を抽出し、ベクトル(数値)にする方法です。
機械学習は数値で特徴を教える必要があるので、文章を学習させたいなら、
文章→数値に変換する必要があります。
from sklearn.feature_extraction.text import TfidfVectorizer
tfidf = TfidfVectorizer(max_features = 200)
X_train = tfidf.fit_transform(train["text"].values)
X_test = tfidf.transform(test["text"].values)
print(X_train.shape, X_test.shape)
y_train = train["target"].values
y_test = test["target"].values
print(y_train.shape, y_test.shape)
# ========== output ==========
# (11314, 200) (7532, 200)
# (11314,) (7532,)これで各文章を200個の特徴にベクトル化しました。
“max_features”は変換後の列数です。
大きいほどデータの表現力が上がりますが、計算が重くなるので注意しましょう。
モデル作成(LightGBM)
学習にはLightGBMを使います。詳しい使い方は以下の記事で解説しています。
>>LightGBMで分類モデルを作る方法
import lightgbm as lgbm
import matplotlib.pyplot as plt
# データ形式の変換
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# パラメータ設定
params = {"objective": "multiclass", # 他クラス分類
"num_class": 20, # クラス数
"verbosity": -1,
}
# ログ保存用の変数
history = {}
# 学習
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
num_boost_round = 100,
callbacks = [
lgbm.callback.record_evaluation(history),
lgbm.callback.early_stopping(10),
],
)
plt.plot(history["training"]["multi_logloss"], label = "train")
plt.plot(history["valid_1"]["multi_logloss"], label = "test")
plt.legend()
plt.show()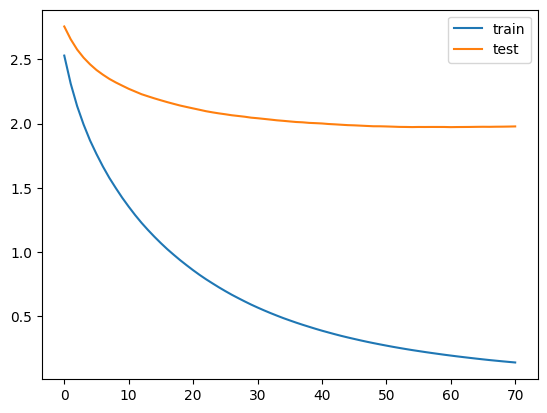
徐々にlossが下がっていれば成功です。
70回目くらいで改善が止まっていますね。
予測結果
predictで予測します。
出力は各ラベルに該当する確率なので、今回は20列あります。
pred = model.predict(X_test).argmax(axis = 1)
print(pred[:5])
print(y_test[:5])
# ========== output ==========
# [ 3 1 15 16 19]
# [ 7 5 0 17 19]argmaxを使って、最も値(確率)の大きい列番号を取りましょう。
5個だけ予測と答えを並べてみると、最後の19だけあっていますね。
正解率も計算してみましょう。
from sklearn.metrics import accuracy_score
print(accuracy_score(pred, y_test))
# ========== output ==========
# 0.3961763143919278正解率は39%でかなり悪いですね。。。
ですが分類モデル自体は完成しているので、精度を高めていきましょう。
max_featuresと予測精度
tfidf = TfidfVectorizer(max_features = 1000)
X_train = tfidf.fit_transform(train["text"].values)
X_test = tfidf.transform(test["text"].values)
print(X_train.shape, X_test.shape)
y_train = train["target"].values
y_test = test["target"].values
print(y_train.shape, y_test.shape)
# ========== output ==========
# (11314, 1000) (7532, 1000)
# (11314,) (7532,)正解率が悪い原因として、tf-idfの表現力が弱かったことが考えられます。
“max_features”を200から1000に上げて列数を増やしてみましょう。
# データ形式の変換
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# パラメータ設定
params = {"objective": "multiclass", # 他クラス分類
"num_class": 20, # クラス数
"verbosity": -1,
}
# ログ保存用の変数
history = {}
# 学習
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
num_boost_round = 100,
callbacks = [
lgbm.callback.record_evaluation(history),
lgbm.callback.early_stopping(10),
],
)
plt.plot(history["training"]["multi_logloss"], label = "train")
plt.plot(history["valid_1"]["multi_logloss"], label = "test")
plt.legend()
plt.show()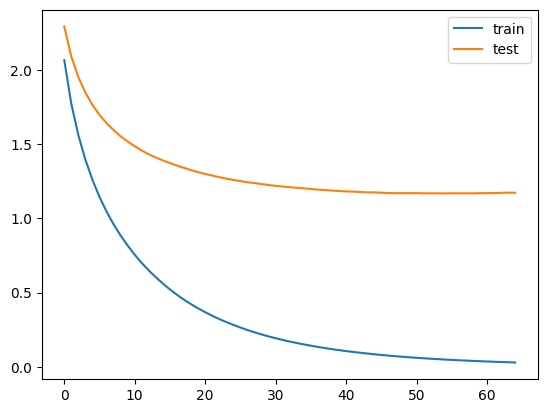
max_features = 200の時と比べてlossが1.5以下まで下がっていますね。
pred = model.predict(X_test).argmax(axis = 1)
print(pred[:5])
print(y_test[:5])
print(accuracy_score(pred, y_test))
# ========== output ==========
# [ 4 12 0 0 19]
# [ 7 5 0 17 19]
# 0.6638343069569835正解率も66%まで上がりました。
もっと精度を伸ばしたいなら”max_features”をさらに増やすこともできます。
ですが列数が多いほど計算時間が長くなることに注意しましょう。
まとめ
今回はtf-idfとLightGBMで自然言語処理モデルを作る方法を解説しました。
CPUで手軽に実装できる方法なのでぜひ試してみてください!
GPUを持っていてさらに精度を高めたい場合は、BERTを試してみましょう。


コメント