
LightGBMは簡単に作れるわりに精度が良く、計算も軽いので、とりあえず最初に作ってみるモデルとして最適です。今回はLightGBMを使って回帰モデルを作る方法を解説します。
分類をやってみたい方は以下の記事を参考にしてください。
>>LightGBMで分類モデルを作る方法
データセット
そもそもデータセットを持っていない人は、scikit-learnに入っているものを使いましょう。
Python実行環境がない場合は、Google Colaboratoryを利用すればOKです。
>>Google Colaboratoryの使い方
import pandas as pd
from sklearn.datasets import load_diabetes
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df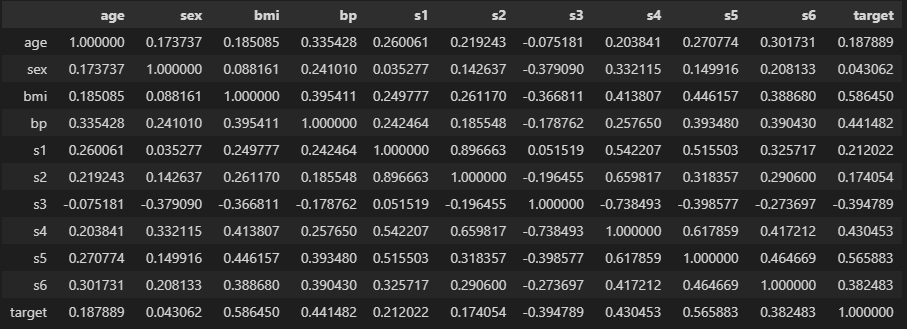
targetが予測したい値です。
import matplotlib.pyplot as plt
plt.scatter(df["bmi"], df["target"], alpha = 0.5)
plt.xlabel("bmi")
plt.ylabel("target")
plt.show()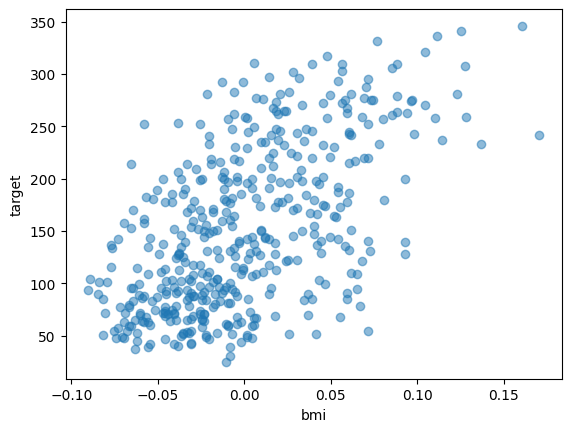
例えばbmiとtargetの関係性はこんな感じです。
モデルにはage ~ s6まで合計10種類の特徴を学習させます。
データ分割
学習を始める前にデータを分割しましょう。
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.1)
features = [c for c in df.columns if c != "target"]
print(features)
#学習用データ
X_train = train[features]
y_train = train["target"].values
#検証用データ
X_test = test[features]
y_test = test["target"].values
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
# (397, 10) (397,)
# (45, 10) (45,)精度を確かめるときに1度答えを教えているデータ(train)を使うと、正解しやすくなります。
なので、精度検証では答えを教えていないデータ(test)を使いましょう。
【関連記事】交差検証でよく使うデータ分割法
モデル作成
import lightgbm as lgbm
# データ形式の変換
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# パラメータ設定
params = {"objective": "regression", # 回帰
"metric": "rmse", # 平均二乗誤差の平方根
"verbosity": -1} # warningなどを出力しない
# 学習
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
)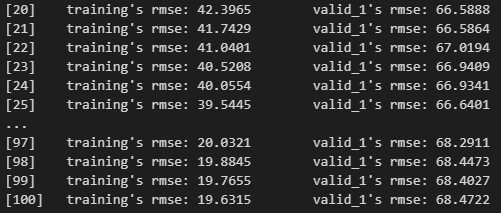
LightGBMは複数回モデルを更新して精度を高めています。
なので上図のように、徐々に精度が上がっている(rmseが下がる)と成功です。
予測結果
import numpy as np
preds = model.predict(X_train)
plt.scatter(y_train, preds, alpha = 0.5)
plt.plot(np.arange(50, 350), np.arange(50, 350), "r-")
plt.xlabel("true")
plt.ylabel("pred")
plt.show()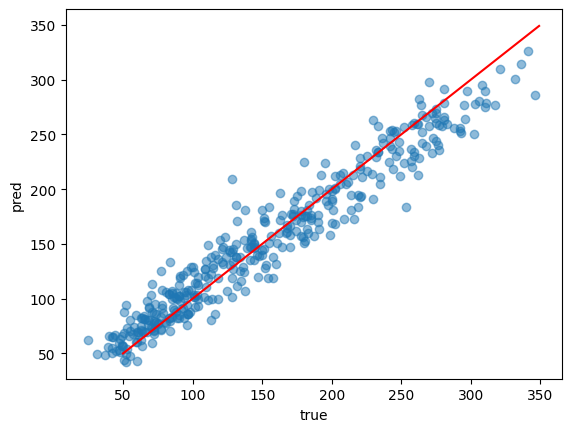
predictで予測できます。
赤線上に乗っているデータはピッタリ正解しています。
だいたい合っていそうですが、これは学習データ(train)だからでもあります。
なので答えを教えていないデータ(test)でも確かめましょう。
preds = model.predict(X_test)
plt.scatter(y_test, preds, alpha = 0.5)
plt.plot(np.arange(50, 350), np.arange(50, 350), "r-")
plt.xlabel("true")
plt.ylabel("pred")
plt.show()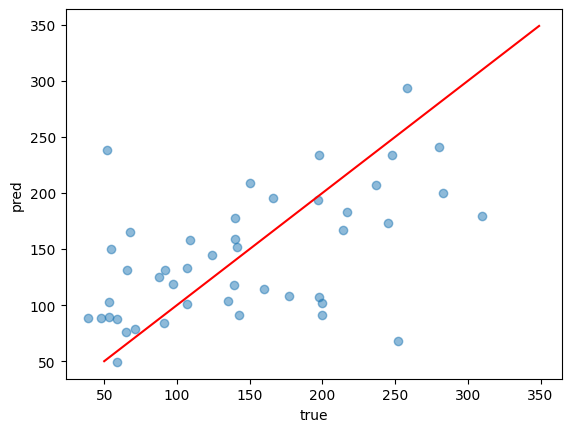
ぼちぼち合っていそうですが、左側のtrueが小さいあたりでは外していそうですね。
このままではわかりにくいので、誤差を計算してみましょう。
from sklearn.metrics import mean_squared_error, r2_score
print(np.sqrt(mean_squared_error(y_test, preds)))
print(r2_score(y_test, preds))
# ========== output ==========
# 68.47217402721692
# 0.3661846850555097平均二乗誤差の平方根とR2を計算しました。
68.4と0.366なのでいまいちですね。
パラメータチューニングとか色々改善の余地がありますが、今回は勉強なので出来合いにしましょう。
特徴量重要度
学習と予測ができたと言っても、結局どんな特徴(列)が重要だったかがわかりにくいですよね。
LightGBMならどの特徴が効いていたかを可視化することができます。
lgbm.plot_importance(model)
plt.show()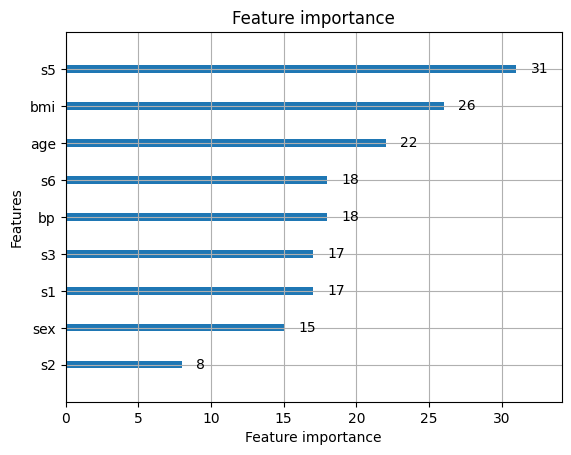
“plot_importance”に作成したモデルを入れると、特徴量の重要度を可視化できます。
デフォルトでは”target”への寄与度にならないので、“importance_type”を”gain”に変えましょう。
lgbm.plot_importance(model, importance_type = "gain")
plt.show()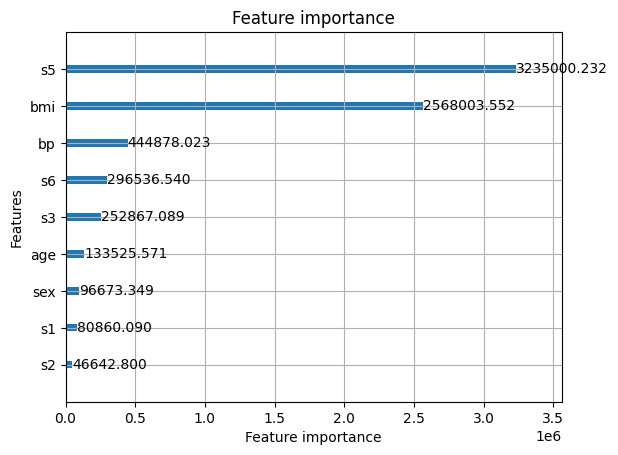
どちらにせよs5とbmiが重要そうですね。
このデータセットは糖尿病の指標に関するものなので、bmiが効いているのも納得です。
もっと詳しく重要度の可視化をしてみたい人はSHAP値を試してください。
>>SHAP値で特徴量の影響度を可視化する方法
まとめ
今回はLightGBMで回帰モデルを作る方法を解説しました。
Kaggleでも実務でも使いやすい優秀なモデルなので、ぜひ実装してみてください。


コメント