
pytorchはtimmやBERT(transformers)が使えるので、非常に優秀なライブラリです。
>>pytorchとtimmで画像分類モデルを作る方法
>>pytorchとBERTで文章分類モデルを作る方法
今回はpytorchで回帰, 二値分類, 他クラス分類のモデルを作る方法を紹介します。
基本的な構造を理解しておけば、モデルや損失関数を変えるだけで様々なタスクに対応できます。
コピペするだけで実装できるので、初心者の方もぜひ挑戦してみてください。
回帰モデル
データセット
import pandas as pd
from sklearn.datasets import load_diabetes
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
“age” ~ “s6″までの特徴量から”target”を予測しましょう。
データ分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.1)
print(train.shape, test.shape)
# ========== output ==========
# (397, 11) (45, 11)“train_test_split”で学習用データと検証用データとに分けました。
“test_size”が0.1なので、10%が検証用になっています。
【関連記事】交差検証でよく使うデータ分割法
標準化
from sklearn.preprocessing import StandardScaler
features = [c for c in df.columns if c != "target"]
print(features)
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
train.head()
# ========== output ==========
# ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
ニューラルネットでモデルを作る場合は、標準化することをお勧めします。
列によって0->1の変化の度合いが違うとうまく学習してくれません。
特徴量をfeaturesとして、標準化を適用しました。
“target”は予測する値なので変換する必要はありません。
Dataset
import torch
from torch.utils.data import Dataset
class CustomData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[features].values[idx]
y = self.data["target"].values[idx]
return x, ytrain_data = CustomData(train)
test_data = CustomData(test)
print(train_data[0])
# ========== output ==========
# (array([ 0.40918598, -0.94365046, 0.12413589, -0.55396748, 0.47526333,
# 0.20581974, 1.40891086, -0.83328086, -0.47916137, -0.9440648 ]), 59.0)[0]を入れると、getitemでidx=0のデータが取り出されます。
出力は(特徴量, “target”)の構造です。
DataLoader
from torch.utils.data import DataLoader
train_dl = DataLoader(train_data, batch_size = 32, shuffle = True, drop_last = True)
test_dl = DataLoader(test_data, batch_size = 32, shuffle = False, drop_last = False)
batch = next(iter(train_dl))
print(len(batch))
print(batch[0].shape)
# ========== output ==========
# 2
# torch.Size([32, 10])DataLoaderを使って、データを小出しにするシステムを作ります。
ニューラルネットでは、小分けしたデータをモデルに渡して学習していきます。
batch_sizeの数だけ出てくるので、今回は32個ずつです。
モデル作成
import torch.nn as nn
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(in_features = len(features), out_features = 16)
self.linear2 = nn.Linear(in_features = 16, out_features = 32)
self.linear3 = nn.Linear(in_features = 32, out_features = 1)
def forward(self, inputs):
x = nn.ReLU()(self.linear1(inputs))
x = nn.ReLU()(self.linear2(x))
logits = self.linear3(x)
return logitsニューラルネットの基礎知識は解説しませんので、下の本を読んでください。
Linearは全結合するだけの層で、in_featuresが入力サイズ、out_featuresが出力サイズです。
Linearから出力されたデータを活性化関数ReLUに入れましょう。
最終的に出力されるlogitsが予測した値になります。
学習と検証
以下のコードがほぼ最小の構成です。
誤差伝播や勾配リセットなど、ニューラルネットの基礎知識は解説しきれないので、
やはり前述の本を参考にしてください。
# モデル呼び出し
model = CustomModel()
# 最適化手法
optimizer = torch.optim.Adam(model.parameters(), lr = 5e-3)
# 損失関数
criterion = nn.MSELoss()
# 学習ログを保存する変数
history = {"train": [], "test": []}
# epochの数だけ学習を繰り返す
for epoch in range(30):
# 学習
model.train()
train_loss = 0
for batch in train_dl:
optimizer.zero_grad()
x = batch[0].float() # 特徴量
y = batch[1].float() # 答え
logits = model(x).squeeze(-1) # 予測
loss = criterion(logits, y) # 誤差計算
loss.backward() # 誤差伝播
optimizer.step() # パラメータ更新
train_loss += loss.item()
train_loss /= len(train_dl)
# 検証
model.eval()
test_loss = 0
with torch.no_grad(): # パラメータ更新をしない
for batch in test_dl:
x = batch[0].float()
y = batch[1].float()
logits = model(x).squeeze(-1)
loss = criterion(logits, y)
test_loss += loss.item()
test_loss /= len(test_dl)
# ログ保存
history["train"].append(train_loss)
history["test"].append(test_loss)これらをepochsの回数繰り返します。今回は30回にしました。
最適化手法のlr(learning_rate)を大きくしています。
学習時はmodel.train()で学習モードにします。
検証時はmodel.eval()とno_grad()でパラメータの更新をしないように設定します。
import matplotlib.pyplot as plt
plt.plot(history["train"], label = "train")
plt.plot(history["test"], label = "test")
plt.legend()
plt.show()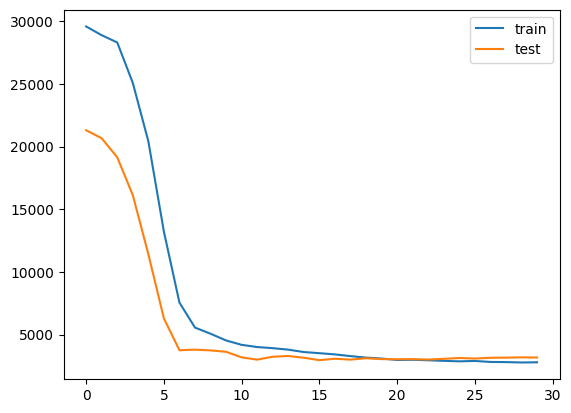
こんな感じで徐々にlossが下がっていれば成功です。
予測
model.eval()
preds = []
targets = []
with torch.no_grad():
for batch in test_dl:
x = batch[0].float()
y = batch[1].float()
logits = model(x).squeeze(-1)
preds += logits.numpy().tolist()
targets += y.numpy().tolist()
print(preds[:5])
print(targets[:5])
# ========== output ==========
# [54.068809509277344, 169.09481811523438, 141.07737731933594, 201.21810913085938, 287.97564697265625]
# [104.0, 229.0, 181.0, 109.0, 310.0]予測するときは検証と同じことをします。
予測値と答えをそれぞれリストにして保存しました。
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
print(np.sqrt(mean_squared_error(targets, preds)))
print(r2_score(targets, preds))
# ========== output ==========
# 55.115998984982106
# 0.4524787513713274平均二乗誤差の平方根とR2スコアを計算しました。
R2スコアが0.45なのでぼちぼちですね。
二値分類モデル
上記の回帰モデルとほとんど変わりません。
変更点は損失関数の定義くらいです。
データセット
import pandas as pd
from sklearn.datasets import load_breast_cancer
data = load_breast_cancer()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
30列の特徴量から”target”が0か1かを分類するモデルを作りましょう。
前処理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
train, test = train_test_split(df, test_size = 0.1, stratify = df["target"])
print(train.shape, test.shape)
features = [c for c in df.columns if c != "target"]
print(len(features))
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
# ========== output ==========
# (512, 31) (57, 31)
# 30データ分割と標準化をしました。
“train_test_split”の”stratify”を設定することで、ラベルの偏りがないように分割しましょう。
例えば学習データにラベル1が含まれなかったら、モデルはすべて0と予測してしまうからです。
Dataset, DataLoader
import torch
from torch.utils.data import Dataset, DataLoader
class CustomData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[features].values[idx]
y = self.data["target"].values[idx]
return x, y
train_data = CustomData(train)
test_data = CustomData(test)
train_dl = DataLoader(train_data, batch_size = 32, shuffle = True, drop_last = True)
test_dl = DataLoader(test_data, batch_size = 32, shuffle = False, drop_last = False)
batch = next(iter(train_dl))
print(len(batch))
print(batch[0].shape)
# ========== output ==========
# 2
# torch.Size([32, 30])Dataset, DataLoaderを作りました。
これも同じことをしているだけです。
特徴量が30個あるので、1バッチのサイズは(32, 30)になっています。
モデル作成
import torch.nn as nn
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(in_features = len(features), out_features = 64)
self.linear2 = nn.Linear(in_features = 64, out_features = 64)
self.linear3 = nn.Linear(in_features = 64, out_features = 1)
def forward(self, inputs):
x = nn.ReLU()(self.linear1(inputs))
x = nn.ReLU()(self.linear2(x))
logits = self.linear3(x)
return logits回帰モデルよりもLinearのユニット数を増やしています。
今回は30列あるので、ユニット数が32だと表現力が足りなさそうだからです。
最後の出力は1列で、これがtargetが0か1かを予測する値になります。
学習と検証
import matplotlib.pyplot as plt
# モデル呼び出し
model = CustomModel()
# 最適化手法
optimizer = torch.optim.Adam(model.parameters(), lr = 3e-3)
# 損失関数
criterion = nn.BCEWithLogitsLoss()
# 学習ログを保存する変数
history = {"train": [], "test": []}
# epochの数だけ学習を繰り返す
for epoch in range(20):
# 学習
model.train()
train_loss = 0
for batch in train_dl:
optimizer.zero_grad()
x = batch[0].float() # 特徴量
y = batch[1].float() # 答え
logits = model(x).squeeze(-1) # 予測
loss = criterion(logits, y) # 誤差計算
loss.backward() # 誤差伝播
optimizer.step() # パラメータ更新
train_loss += loss.item()
train_loss /= len(train_dl)
# 検証
model.eval()
test_loss = 0
with torch.no_grad(): # パラメータ更新をしない
for batch in test_dl:
x = batch[0].float()
y = batch[1].float()
logits = model(x).squeeze(-1)
loss = criterion(logits, y)
test_loss += loss.item()
test_loss /= len(test_dl)
# ログ保存
history["train"].append(train_loss)
history["test"].append(test_loss)
plt.plot(history["train"], label = "train")
plt.plot(history["test"], label = "test")
plt.legend()
plt.show()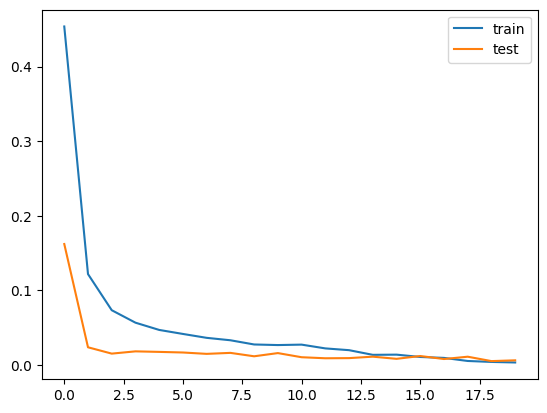
損失関数をBCEWithLogitsLossにしています。
これは、モデルの出力にシグモイド関数をかけ、
0~1の数値(確率)に変換してからラベルとの誤差(loss)を計算してくれます。
回帰モデルと同じように徐々にlossが減少していれば成功です。
予測
model.eval()
preds = []
targets = []
with torch.no_grad():
for batch in test_dl:
x = batch[0].float()
y = batch[1].float()
logits = model(x).squeeze(-1)
preds += logits.sigmoid().numpy().tolist()
targets += y.numpy().tolist()
print(preds[:5])
print(targets[:5])
# ========== output ==========
# [6.920229389528743e-10, 5.160360390957272e-30, 0.04943035542964935, 6.047450870347686e-30, 0.9956806898117065]
# [0.0, 0.0, 0.0, 0.0, 1.0]予測するときはシグモイド関数(sigmoid)を使いましょう。
これで0~1の確立として予測できます。
import numpy as np
from sklearn.metrics import accuracy_score
print(accuracy_score(targets, np.array(preds).round()))
# ========== output ==========
# 1.0最後に確率が0.5以上ならtarget=1として正解率を計算しました。100%ですね。
他クラス分類モデル
これも回帰モデルや2値分類モデルとほとんど同じです。
損失関数とモデルの出力列数に気をつけましょう。
データセット
import pandas as pd
from sklearn.datasets import load_iris
data = load_iris()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
“sepal length” ~ “petal width”の特徴量を使って”target”を予測します。
“target”は0,1,2の3種類あります。
前処理
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
train, test = train_test_split(df, test_size = 0.1, stratify = df["target"])
print(train.shape, test.shape)
features = [c for c in df.columns if c != "target"]
print(features)
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
# ========== output ==========
# (135, 5) (15, 5)
# ['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']データ分割と標準化をしました。
ここでも”stratify”を設定して、ラベルが均一になるようにデータ分割しましょう。
Dataset, DataLoader
import torch
from torch.utils.data import Dataset, DataLoader
class CustomData(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
x = self.data[features].values[idx]
y = self.data["target"].values[idx]
return x, y
train_data = CustomData(train)
test_data = CustomData(test)
train_dl = DataLoader(train_data, batch_size = 32, shuffle = True, drop_last = True)
test_dl = DataLoader(test_data, batch_size = 32, shuffle = False, drop_last = False)
batch = next(iter(train_dl))
print(len(batch))
print(batch[0].shape)
# ========== output ==========
# 2
# torch.Size([32, 4])Dataset, DataLoaderを作りました。
今回の特徴量は4つしかありません。
モデル作成
import torch.nn as nn
class CustomModel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(in_features = len(features), out_features = 32)
self.linear2 = nn.Linear(in_features = 32, out_features = 64)
self.linear3 = nn.Linear(in_features = 64, out_features = 3) # クラス数
def forward(self, inputs):
x = nn.ReLU()(self.linear1(inputs))
x = nn.ReLU()(self.linear2(x))
logits = self.linear3(x)
return logitsここで重要なのは、最後に出力するout_featuresの値です。
今回は3種類のクラスがあるので、out_features = 3にする必要があります。
学習と検証
import matplotlib.pyplot as plt
# モデル呼び出し
model = CustomModel()
# 最適化手法
optimizer = torch.optim.Adam(model.parameters(), lr = 5e-3)
# 損失関数
criterion = nn.CrossEntropyLoss()
# 学習ログを保存する変数
history = {"train": [], "test": []}
# epochの数だけ学習を繰り返す
for epoch in range(20):
# 学習
model.train()
train_loss = 0
for batch in train_dl:
optimizer.zero_grad()
x = batch[0].float() # 特徴量
y = batch[1].long() # 答え
logits = model(x) # 予測
loss = criterion(logits, y) # 誤差計算
loss.backward() # 誤差伝播
optimizer.step() # パラメータ更新
train_loss += loss.item()
train_loss /= len(train_dl)
# 検証
model.eval()
test_loss = 0
with torch.no_grad(): # パラメータ更新をしない
for batch in test_dl:
x = batch[0].float()
y = batch[1].long()
logits = model(x)
loss = criterion(logits, y)
test_loss += loss.item()
test_loss /= len(test_dl)
# ログ保存
history["train"].append(train_loss)
history["test"].append(test_loss)
plt.plot(history["train"], label = "train")
plt.plot(history["test"], label = "test")
plt.legend()
plt.show()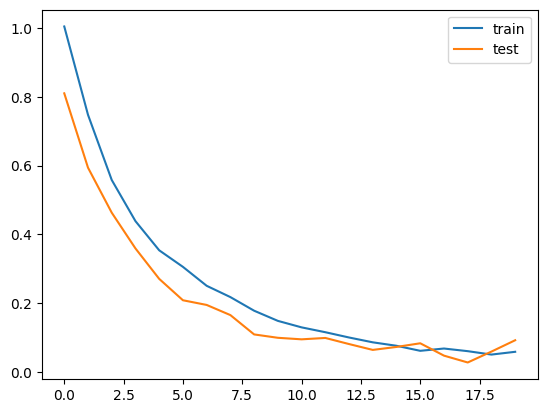
損失関数をCrossEntoropyLossにし、答えのデータyを整数型のlongにしましょう。
モデルの最終出力の列数が3なので、この値を元に各ラベルに該当する確率が計算されます。
徐々にlossが下がっていれば成功です。
予測
import numpy as np
model.eval()
preds = []
targets = []
with torch.no_grad():
for batch in test_dl:
x = batch[0].float()
y = batch[1].float()
logits = model(x).squeeze(-1)
preds.append(nn.Softmax(dim = 1)(logits).numpy())
targets += y.numpy().tolist()
preds = np.concatenate(preds, axis = 0)
print(preds[:5])
print(targets[:5])
# ========== output ==========
# [[9.9959892e-01 4.0105358e-04 3.5546350e-08]
# [5.4718492e-07 1.6252339e-03 9.9837422e-01]
# [1.2093678e-03 9.3166929e-01 6.7121267e-02]
# [5.8763558e-08 7.2355419e-05 9.9992764e-01]
# [2.0213486e-06 9.5684431e-04 9.9904114e-01]]
# [0.0, 2.0, 1.0, 2.0, 2.0]予測した出力の列数はクラス数と同じになります。
なので、今回は3列あり、Softmax関数に通すことで各ラベルの確立にできます。
from sklearn.metrics import accuracy_score
print(accuracy_score(targets, preds.argmax(axis = 1)))
# ========== output ==========
# 0.9333333333333333最も確立の大きい列番号を予測ラベルにしました。
正解率が93.3%なのでかなりいいですね。
まとめ
今回はpytorchでモデルを作る方法を解説しました。
画像モデルや自然言語モデルが作りやすいライブラリなので、使えるようになっておきたいですね。


コメント