

GradCAMで画像分類モデルが見ている場所を確認したかったのですが、
意味不明でエラーを連発しました。
何とか使えるようになったので、初心者向けに共有しておきます。
注意点として、この記事に書かれていることが最新とは限りません。
エラーが起きたときは、まず上記リンクにあるGradCAMの最新情報を確認してください。
データセット準備
今回はKaggleにある“Dogs vs. Cats”からデータを頂きます。
Kaggleのデータを記事に載せるのはよろしくないので、基本的にはコードのみの解説です。
import os
len(os.listdir("/content/train")) # content/trainに画像を入れました画像は25000枚あります。
実際に確認したい人は、Kaggleに登録して上記コンペからデータを見てください。
最後はPixabayにある画像を使って、正しく分類できているか確認しましょう。
ライブラリ
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import glob
import cv2
!pip install albumentations==0.4.5 -q #ToTensorV2があるversion
import albumentations as A
from albumentations.pytorch.transforms import ToTensorV2
!pip install timm -q
import timm
import torch
from torch import nn, optim
from torch.utils.data import Dataset, DataLoader
from sklearn.model_selection import KFold, StratifiedKFold
from tqdm.notebook import tqdm
from sklearn.metrics import accuracy_score説明は省略します。
timmで簡単に高精度なモデルを実装できるので、下の記事を参考にどうぞ。
【関連記事】pytorchで画像分類モデルを作る方法
データセット
image_store = glob.glob("/content/train/*")
print(len(image_store))
print(image_store[0])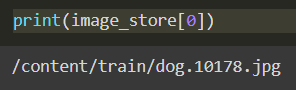
Kaggleから画像を入れています。
image_storeは画像のパスが入っているリストです。
Google Colaboratoryに画像を入れているので、”/content”になっています。
データはご自身で用意するか、Kaggleに登録して同じデータを使ってください。
transform = A.Compose([
A.Resize(256, 256),
A.Normalize(),
ToTensorV2()
])
class DS(Dataset):
def __init__(self, data, transform = transform):
self.data = data #画像のパスのリスト
self.transform = transform
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
path = self.data[idx]
target = path.split("/")[-1][:3] #ファイル名の最初の3文字がdogかcatになっている
if target == "dog": #dogはlabel0, catはlabel1にする
label = 0
else:
label = 1
image = cv2.imread(path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
image = self.transform(image = image)["image"]
label = torch.tensor(label)
return image, label画像のパスからdogとcatを識別し、それぞれラベル0と1を割り当てました。
ds = DS(image_store)
for i in range(5):
plt.imshow(ds[i][0].permute(1, 2, 0))
plt.title(ds[i][1])
plt.show()画像を確認するために実行しています。
モデル
DEVICE = "cuda" if torch.cuda.is_available() else "cpu"
print(DEVICE)計算が重いので、可能な方はGPUを使いましょう。
model = timm.create_model("tf_efficientnet_b0_ns", pretrained = True, num_classes = 2) #efficientnetb0, 事前学習あり
model.to(DEVICE) #GPUがつかえるなら早くなる
optimizer = optim.Adam(params = model.parameters()) #無難なやつ
criterion = nn.CrossEntropyLoss() #他クラス分類事前学習済みモデルをダウンロードしました。
この方法についても過去の記事で解説しています。
犬or猫の他クラス分類なのでCrossEntropyLossを使いました。
学習と検証
学習
kf = KFold(n_splits = 5, shuffle = True, random_state = 0) #5分の1を検証データにする
for train_idx, valid_idx in kf.split(image_store):
train_image = np.array(image_store)[train_idx]
valid_image = np.array(image_store)[valid_idx]
train_ds = DS(train_image)
valid_ds = DS(valid_image)
train_dl = DataLoader(train_ds, batch_size = 64, shuffle = True, drop_last = True)
valid_dl = DataLoader(valid_ds, batch_size = 64 * 2, shuffle = False, drop_last = False)
for epoch in range(3): #増やしてもいい
model.train()
train_loss = 0
for batch in tqdm(train_dl):
optimizer.zero_grad() #リセット
image = batch[0].float().to(DEVICE)
label = batch[1].long().to(DEVICE)
preds = model(image).squeeze(-1) #予測
loss = criterion(preds, label) #誤差計算
loss.backward() #誤差伝播
optimizer.step() #改善
train_loss += loss.item()
train_loss /= len(train_dl)
model.eval()
valid_loss = 0
with torch.no_grad():
for batch in tqdm(valid_dl):
image = batch[0].float().to(DEVICE)
label = batch[1].long().to(DEVICE)
preds = model(image).squeeze(-1)
loss = criterion(preds, label)
valid_loss += loss.item()
valid_loss /= len(valid_dl)
print(epoch, train_loss, valid_loss)
break #1foldだけで終わり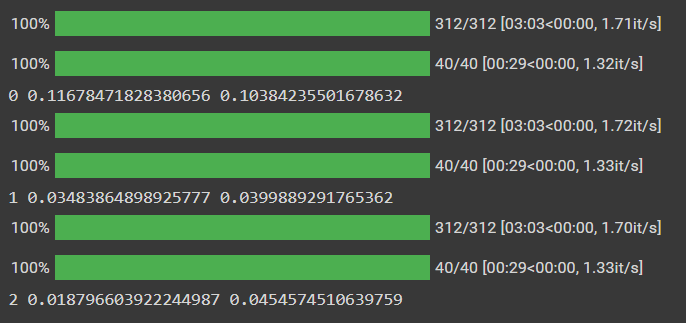
データを5分割し、1つ目のFoldだけ学習させました。
検証
oof_pred = []
oof_true = []
model.eval()
with torch.no_grad():
for batch in tqdm(valid_dl):
image = batch[0].float().to(DEVICE)
label = batch[1].long().to(DEVICE)
preds = model(image).squeeze(-1)
preds = preds.cpu().numpy().argmax(axis = 1)
oof_pred.append(preds)
oof_true.append(label.cpu().numpy())
oof_pred = np.concatenate(oof_pred, axis = 0)
oof_true = np.concatenate(oof_true, axis = 0)
accuracy_score(oof_true, oof_pred)
# ========== outputs ==========
# 0.9868正解率は98%程度です。
予測
Kaggleのデータ以外の画像で、犬or猫を判別できるか確かめましょう。
dog_image = cv2.imread("/content/drive/MyDrive/Kaggle/Chiemsee2016.jpg")
dog_image = cv2.cvtColor(dog_image, cv2.COLOR_BGR2RGB)
cat_image = cv2.imread("/content/drive/MyDrive/Kaggle/Susann Mielke.jpg")
cat_image = cv2.cvtColor(cat_image, cv2.COLOR_BGR2RGB)
plt.imshow(dog_image)
plt.show()
plt.imshow(cat_image)
plt.show()
tensor型にしてラベルを予測してみます。
dog_input_image = transform(image = dog_image)["image"].float().unsqueeze(0).to(DEVICE)
cat_input_image = transform(image = cat_image)["image"].float().unsqueeze(0).to(DEVICE)
with torch.no_grad():
preds = model(torch.cat([dog_input_image, cat_input_image], dim = 0))
preds = preds.cpu().numpy().argmax(axis = 1)
print(preds)
# ========== outputs ==========
# [0 1]犬がラベル0、猫がラベル1なので、正解ですね。
GradCAM
インストール
GitHubにあるpytorch-grad-camを使います。
!pip install grad-cam -q
from pytorch_grad_cam import GradCAM
from pytorch_grad_cam.utils.image import show_cam_on_image
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget設定
target_layers = [model.conv_head]
cam = GradCAM(model = model, target_layers = target_layers, use_cuda = torch.cuda.is_available())target_layersはモデルによって違います。
target_layersに該当する層で、重みをヒートマップにしているみたいです。
例えばefficientnetを使うなら”conv_head”が対象らしいです。
どれを使えばいいかはGitHubのソースに書かれているので、使いたいモデルに合わせましょう。
また、リストで渡す必要があるので[]で囲んでください。
可視化
まずは犬の画像で可視化してみましょう。
input_tensor = dog_input_image #(batch_size, channel, height, width)
vis_image = cv2.resize(dog_image, (256, 256)) / 255.0 #(height, width, channel), [0, 1]
label = [ClassifierOutputTarget(0)] #犬のラベルは0
print(input_tensor.shape, vis_image.shape)input_tensorはモデルに入れる画像(torch型)で、バッチサイズの次元も必要です。
vis_imageは表示する画像(numpy配列)を入れましょう。
モデルに入れるinput_tensorと同じサイズで、0~1の正則化が必要です。
ラベルは犬なので0にしました。
grayscale_cam = cam(input_tensor = input_tensor, targets = label)
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(vis_image, grayscale_cam, use_rgb = True)
plt.imshow(visualization)
plt.show()さっき用意したinput_tensorとlabelとで、ヒートマップを得ます。
show_cam_on_imageに元の画像(numpy)とヒートマップを入れると画像が帰ってきます。
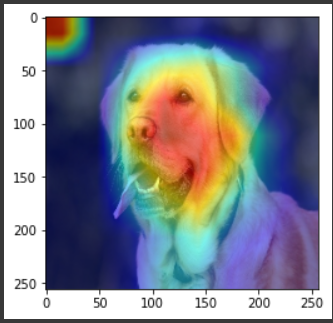
顔全体をみて犬だと判断してくれてますね!!
input_tensor = cat_input_image #(batch_size, channel, height, width)
vis_image = cv2.resize(cat_image, (256, 256)) / 255.0 #(height, width, channel), [0, 1]
label = [ClassifierOutputTarget(1)]
grayscale_cam = cam(input_tensor = input_tensor, targets = label)
grayscale_cam = grayscale_cam[0, :]
visualization = show_cam_on_image(vis_image, grayscale_cam, use_rgb = True)
plt.imshow(visualization)
plt.show()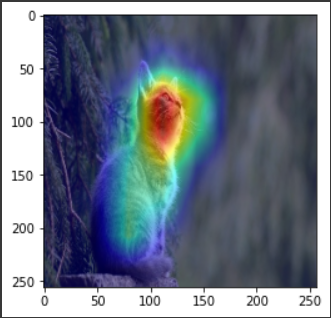
猫の画像もこのとおりです。ラベルが1に変わるので注意しましょう。
これも顔を見て猫だと判定してくれていますね。
まとめ
今回はGradCAMで画像分類モデルが見ている場所を確認しました。
精度改善のために使えそうですね。


コメント
サイトの内容、興味深く拝見させていただきました。
一点質問があります。grad cam の部分なのですが、
grayscale_cam = cam(input_tensor = input_tensor, target_category = label)
の部分で
TypeError: __call__() got an unexpected keyword argument ‘target_category’
というエラーが起きてしまいました。
何か解決策がありましたらご教示ください。
現在は、
from pytorch_grad_cam.utils.model_targets import ClassifierOutputTarget
label = 0ならlabel = [ClassifierOutputTarget(0)]とし、
grayscale_cam = cam(input_tensor=input_tensor, targets=label)とすれば実行できます。
この記事に書かれていることが常に最新とは限りませんので、
不明点があればpytorch-grad-camのgithubにあるREADMEを参照するほうが確実です。