
XGBoostは実装が簡単なわりに精度が良いので、初心者にもおすすめなモデルです。
今回は回帰モデルの作り方を解説します。
データセット
そもそも使えるデータを持ってない。。。
という方は、scikit-learnにあるデータを使いましょう。
Pythonを実行する環境がないなら、Google Colaboratoryがおすすめです。
>>Google Colaboratoryの使い方
import pandas as pd
from sklearn.datasets import load_diabetes
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
import matplotlib.pyplot as plt
plt.scatter(df["bmi"], df["target"], alpha = 0.5)
plt.xlabel("bmi")
plt.ylabel("target")
plt.show()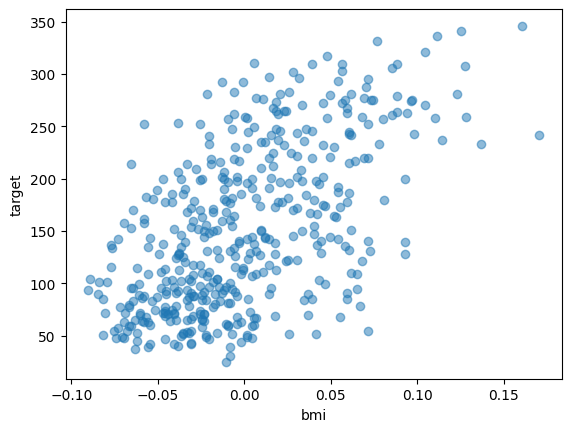
targetが予測したいデータです。このようにbmiと関係性が見られます。
今回はage ~ s6までの10個の列を使って学習させましょう。
データ分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.1)
print(train.shape, test.shape)
# ========== output ==========
# (397, 11) (45, 11)train_test_splitで学習用データと検証用データとにわけます。
test_size = 0.1にすると10%が検証用になります。
【関連記事】交差検証でよく使うデータ分割法
モデルの精度を評価する際は、答えの知らない検証用データを使いましょう。
features = [c for c in df.columns if c != "target"]
print(features)
#学習用データ
X_train = train[features]
y_train = train["target"].values
#検証用データ
X_test = test[features]
y_test = test["target"].values
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
# (397, 10) (397,)
# (45, 10) (45,)モデル作成
import xgboost as xgb
# データ形式の変換
dtrain = xgb.DMatrix(X_train, y_train)
dtest = xgb.DMatrix(X_test, y_test)
# パラメータ設定
# regression: 回帰, squarederror: 二乗誤差
params = {"objective": "reg:squarederror"}
# 学習
model = xgb.train(
params = params,
dtrain = dtrain,
evals = [(dtrain, "train"), (dtest, "test")],
)これだけで学習が実行できます。
ぱっと見は意味不明でも、一度作ってみたら簡単ですよ。
出力は以下のイメージです。
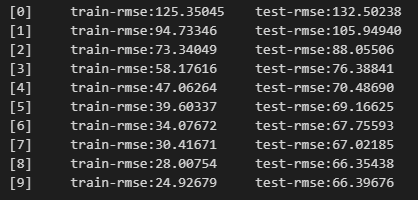
XGBoostは学習と検証を繰り返し、徐々に精度を上げていくモデルです。
なので、上図のように各回での学習データと検証データでの精度が出力されます。
回帰モデルを作りたいなら”objective”は”reg:squarederror”にします。
パラメータの項目についての詳細は公式ドキュメントを見るといいですよ。
予測結果
import numpy as np
preds = model.predict(dtrain)
plt.scatter(y_train, preds, alpha = 0.5)
plt.plot(np.arange(50, 350), np.arange(50, 350), "r-")
plt.show()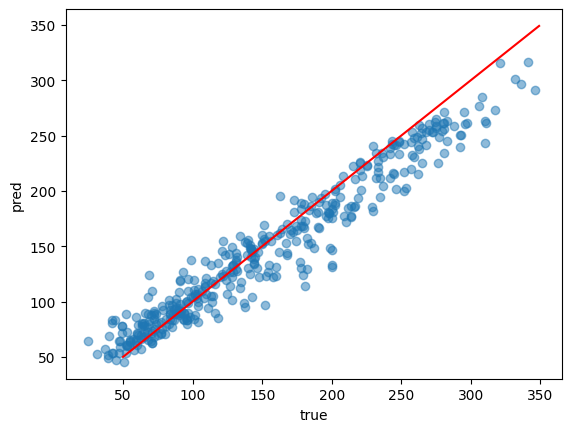
predictで予測できます。
散布図で正解と予測を見てみました。赤線に乗っていたら正解です。
おおよそ正解していますが、これは学習データ(train)だからということもあります。
つまり答えを教えているデータだから精度が高いです。
なので、検証データ(test)でも見てみましょう。
preds = model.predict(dtest)
plt.scatter(y_test, preds, alpha = 0.5)
plt.plot(np.arange(50, 350), np.arange(50, 350), "r-")
plt.xlabel("true")
plt.ylabel("pred")
plt.show()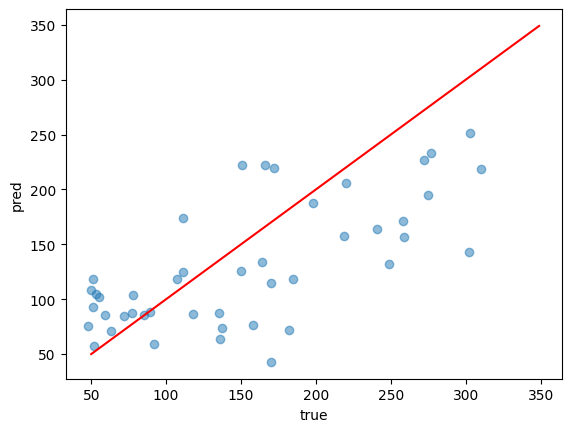
こんな感じです。
図で見ているだけでは精度がわかりにくいので、誤差を計算してみましょう。
from sklearn.metrics import mean_squared_error
print(np.sqrt(mean_squared_error(y_test, pred)))
# ========== output ==========
# 66.3967555643605誤差はおおよそ66.4でした。
特徴量重要度
ここまででモデルを作ることができましたが、
一体どんな特徴(列)が効いているのかわかりませんよね。
XGBoostならどの特徴が効いているかを可視化することができます。
xgb.plot_importance(model)
plt.show()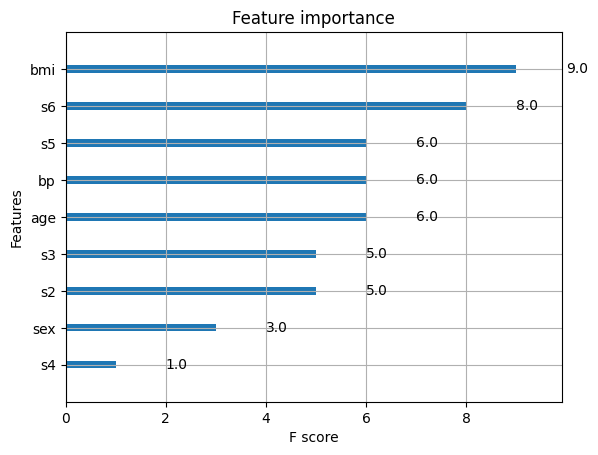
plot_importanceに作成したモデルを入れると、特徴量の重要度を出してくれます。
ただデフォルトでは、どれだけ予測に寄与したかを示すわけではないようです。
予測への寄与度を知りたいなら、“importance_type”を”gain”に変えましょう。
xgb.plot_importance(model, importance_type = "gain")
plt.show()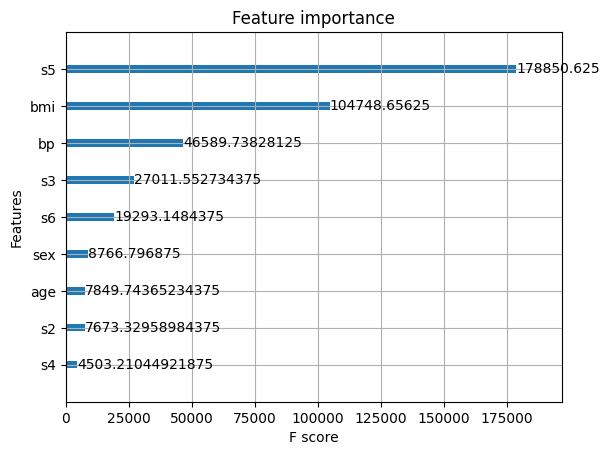
どちらの結果にせよ、s5とbmiが重要みたいですね。
このデータセットは糖尿病に関するものらしいので、bmiが効くのも納得です。
まとめ
今回はXGBoostで回帰モデルを作る方法を解説しました。
似たようなアルゴリズムでLightGBMがあります。
こちらも同じくらい簡単に作れるわりに精度が高く、計算も軽いので、ぜひ挑戦してみてください。


コメント