
SHAP値(シャープレイ値)を計算すると、各特徴量がどれだけ予測に影響するか見ることができます。
もともとはゲームにおいてどのプレイヤーが貢献しているかを確かめるために使ってたみたいです。
インストール
#!pip install -q shap # インストールされてないなら実行する
import shapまずはshapを入れておきましょう。
もともとのドキュメントはこちらです。
もしエラーとかが起きたら最新情報が変わっているかもしれないので、読んでみましょう。
回帰モデル
データの内容とモデルの学習について、詳しいことはこちらの記事で解説しています。
データセットと学習
import numpy as np
import pandas as pd
from sklearn.datasets import load_diabetes
from sklearn.model_selection import train_test_split
import lightgbm as lgbm
import matplotlib.pyplot as plt
from sklearn.metrics import mean_squared_error, r2_score
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
train, test = train_test_split(df, test_size = 0.1)
features = [c for c in df.columns if c != "target"]
#学習用データ
X_train = train[features]
y_train = train["target"].values
#検証用データ
X_test = test[features]
y_test = test["target"].values
# データ形式の変換
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# パラメータ設定
params = {"objective": "regression",
"metric": "rmse",
"verbosity": -1,
"num_leaves": 2,
}
# 学習
history = {}
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
num_boost_round = 300,
callbacks = [lgbm.callback.record_evaluation(history), lgbm.callback.early_stopping(10)],
)
plt.plot(history["training"]["rmse"], label = "train")
plt.plot(history["valid_1"]["rmse"], label = "test")
plt.legend()
plt.show()
pred = model.predict(X_test)
print(np.sqrt(mean_squared_error(y_test, pred)))
print(r2_score(y_test, pred))“load_diabetes”という糖尿病に関するデータセットで、LightGBMを使って学習しています。
shap_values
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train)“TreeExplainer”にモデルを入れます。ツリー系のモデルを説明するという意味ですね。
“shap_values”に特徴量を入れると、SHAP値を計算してくれます。
summary_plot
shap.summary_plot(shap_values, X_train)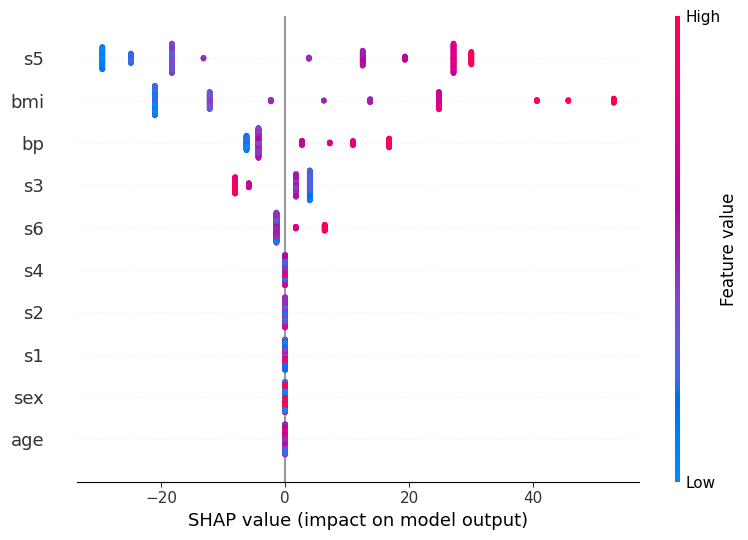
“summary_plot”で全特徴量の影響度を可視化できます。
0が影響度なしで、プラスに大きいほど目的変数を大きくする傾向にあります。
マイナスなら、目的変数を減らします。
それぞれの特徴の大小は赤青の色で示されています。
上図でいうと、”s5″が大小どちらにも効いていて、”bmi”も重要みたいですね。
このデータは糖尿病に関するものなので、”bmi”が効くのも妥当です。
dependence_plot
shap.dependence_plot("bmi", shap_values, X_train)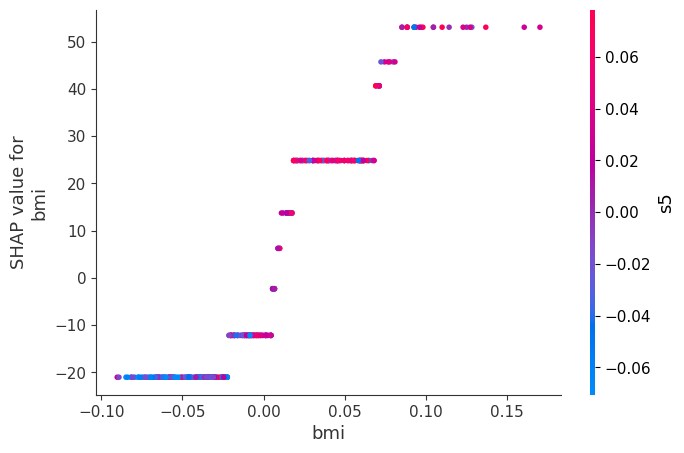
“dependence_plot”は1つの特徴量に対してSHAP値の変化を見ることができます。
“bmi”が小さいほどSHAP値が小さくなり、大きいほどSHAP値も大きくなっていますね。
赤青の色は第2変数の影響度を示しています。
赤いほど”s5″の値が大きく、青いほど小さいという意味です。
force_plot
shap.initjs()
shap.force_plot(explainer.expected_value, shap_values[0], X_train.columns)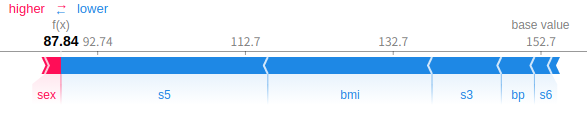
“force_plot”で、1つの予測において各特徴がどのように影響しあっているのか見ることができます。
上図のサンプルなら、”s5″や”bmi”が大きく値を下げる効果があるみたいですね。
こんな感じで、shapを使えばどの特徴が効いて予測をしているのかを見ることができます。
分類モデル
使っているデータやモデルの解説はこちらです。
データセットと学習
import pandas as pd
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
import lightgbm as lgbm
import matplotlib.pyplot as plt
from sklearn.metrics import accuracy_score
data = load_breast_cancer()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
train, test = train_test_split(df, test_size = 0.1, stratify = df["target"])
features = [c for c in df.columns if c != "target"]
# 学習用データ
X_train = train[features]
y_train = train["target"].values
# 検証用データ
X_test = test[features]
y_test = test["target"].values
# データ形式の変換
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
# パラメータ設定
params = {"objective": "binary", # 二値分類
"verbosity": -1,
}
# 学習
history = {}
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
num_boost_round = 300,
callbacks = [lgbm.callback.record_evaluation(history), lgbm.callback.early_stopping(10)],
)
plt.plot(history["training"]["binary_logloss"], label = "train")
plt.plot(history["valid_1"]["binary_logloss"], label = "test")
plt.legend()
plt.show()
pred = model.predict(X_test).round()
print(accuracy_score(y_test, pred))“load_breast_cancer”は乳がんかどうかを判定するデータです。
ラベル0は陰性で1が陽性であり、これを分類するモデルを作りました。
shap_values
explainer = shap.TreeExplainer(model)
shap_values = explainer.shap_values(X_train)
print(len(shap_values))
# ========== output ==========
# 22値分類では”shap_values”が2つ出力されます。
それぞれラベルを0にする影響度、1にする影響度が入っています。
summary_plot
shap.summary_plot(shap_values[1], X_train)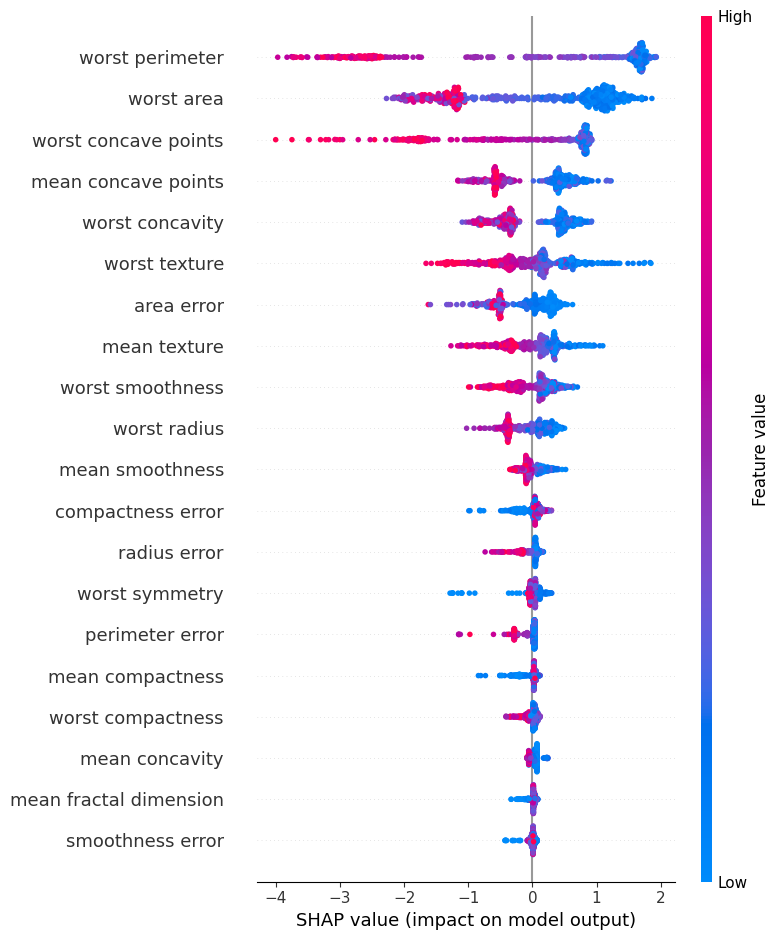
回帰モデルと同様に”summary_plot”を作ることができます。
shap_values[1]にして、ラベルを1にする影響度を表示しています。
dependence_plot
shap.dependence_plot("worst perimeter", shap_values[1], X_train)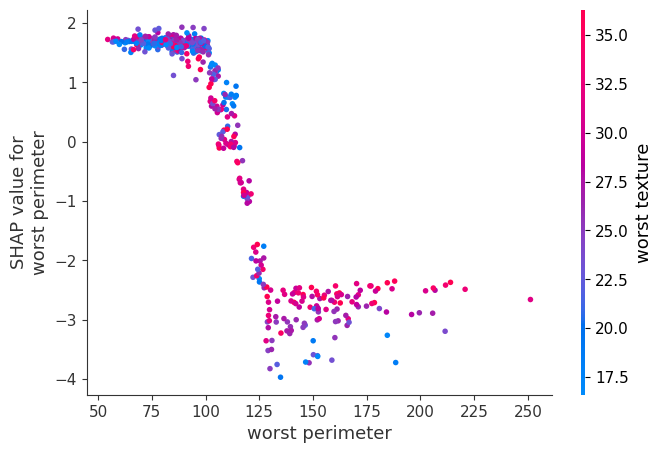
“dependence_plot”を表示しました。
“worst perimeter”が100以下だとshap値が大きい、つまり陽性になる傾向にあるみたいですね。
shap.dependence_plot("worst perimeter", shap_values[0], X_train)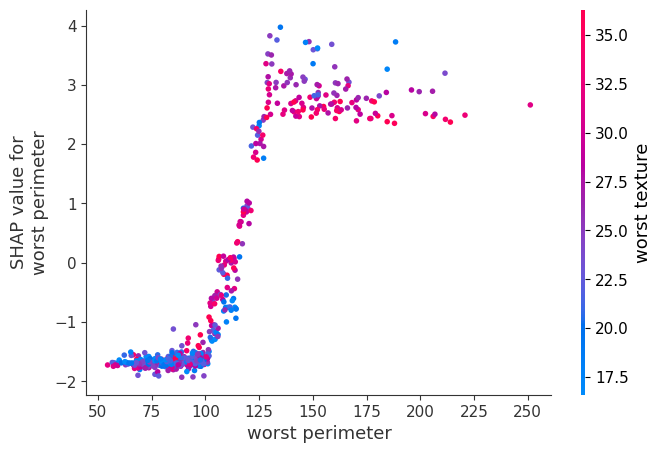
ちなみに、shap_values[0]を使うとこのように上下反転します。
この場合はラベル0となる影響度なので、さっきと真逆になるからですね。
force_plot
shap.initjs()
shap.force_plot(explainer.expected_value[1], shap_values[1][0], X_train.columns)
“force_plot”もこのように表示できます。
やはり”worst perimeter”が大きく影響しており、他にも”worst area”が重要みたいですね。
まとめ
今回はSHAP値を求めて、各特徴がどのように影響しているか可視化する方法を解説しました。
モデル精度を高めたり、分析の糸口を見つけるために使えそうですね。

コメント