

TensorFlow(Keras)で機械学習モデルを作る方法を解説します。
ディープラーニングをするライブラリとして、Pytorchも有名ですが、
TensorFlowならTPUを使いやすいメリットがあります。
>>TensorFlow(Keras)とTPUを使って機械学習をする方法
データセット
load_diabetes
import pandas as pd
from sklearn.datasets import load_diabetes
data = load_diabetes()
df = pd.DataFrame(data["data"], columns = data["feature_names"])
df["target"] = data["target"]
df
“age” ~ “s6″までの特徴量を使って、”target”を予測しましょう。
データ分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(df, test_size = 0.1)
print(train.shape, test.shape)
# ========== output ==========
# (397, 11) (45, 11)“train_test_split”で学習用データと検証用データとに分けました。
10%が検証用に割り当てられています。
【関連記事】交差検証でよく使うデータ分割法
標準化
from sklearn.preprocessing import StandardScaler
features = [c for c in df.columns if c != "target"]
print(features)
scaler = StandardScaler()
train[features] = scaler.fit_transform(train[features])
test[features] = scaler.transform(test[features])
train.head()
# ========== output ==========
# ['age', 'sex', 'bmi', 'bp', 's1', 's2', 's3', 's4', 's5', 's6']
データを標準化して、各列での変化の度合いを揃えておきます。
例えば”age”が1増えるのと”bmi”が1増えるのとではスケールが全く異なるので、
変換する前の状態だとうまくAIモデルが学習できないからです。
特徴量
X_train = train[features].values
y_train = train["target"].values
X_test = test[features].values
y_test = test["target"].values
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== output ==========
# (397, 10) (397,)
# (45, 10) (45,)モデルに入れる特徴量をX、予測したい答えをyにしました。
モデル作成
import tensorflow as tf
import tensorflow.keras.layers as L
import tensorflow.keras.models as M
def get_model(num_features):
# 特徴量を受け取る層
inputs = L.Input(shape = num_features)
# 全結合と活性化関数
x = L.Dense(units = 16, activation = "relu")(inputs) # 1層目
x = L.Dense(units = 32, activation = "relu")(x) # 2層目
x = L.Dense(units = 32, activation = "relu")(x) # 3層目
# 最終出力層
outputs = L.Dense(units = 1, activation = "linear")(x)
# 定義した層を使ってモデルを作る
model = M.Model(inputs = inputs, outputs = outputs)
# 最適化手法と損失関数を定義
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate = 5e-3),
loss = "mse",
)
return model
# モデルの呼び出し
model = get_model(len(features))
model.summary()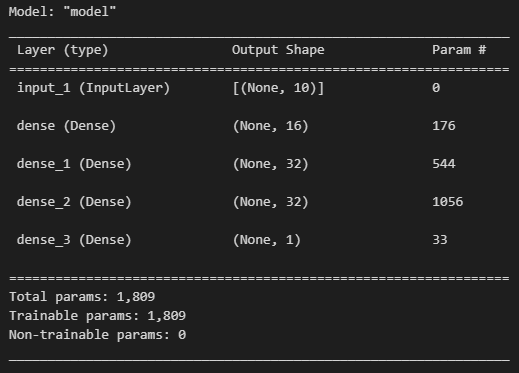
特徴量を受け取って、Dense層で表現を学習し、最後に1次元にして予測値にするイメージです。
“summary”を使うと中身が見れます。
学習と検証
history = model.fit(
X_train, y_train, # 学習用データ
validation_data = (X_test, y_test), # 検証用データ
epochs = 30, # 学習回数
batch_size = 32, # データを小分けするサイズ
)
“fit”で学習を開始します。
ニューラルネットでは”batch_size”ごとにデータを小分けしてモデルに渡して学習させます。
“epochs”は学習回数です。徐々にlossが下がっていることがわかると思います。
import matplotlib.pyplot as plt
plt.plot(history.history["loss"], label = "train")
plt.plot(history.history["val_loss"], label = "test")
plt.legend()
plt.show()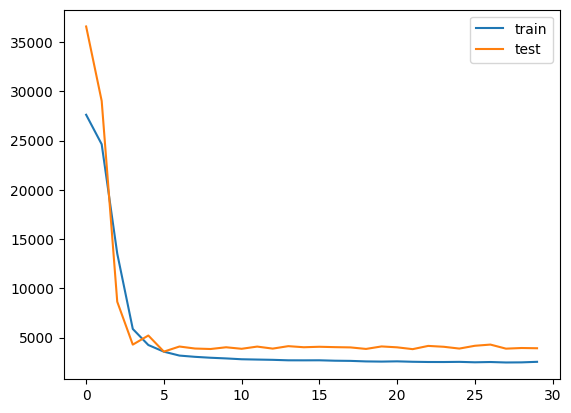
“history”には学習結果が保存されています。
可視化すると確かにlossが下がっていますね。
予測
preds = model.predict(X_test).reshape(-1)
print(preds[:5])
print(y_test[:5])
# ========== output ==========
# [177.78813 230.17897 288.7776 160.47916 262.31384]
# [221. 232. 336. 262. 281.]“predict”で予測できます。だいたいあっていそうですね。
import numpy as np
from sklearn.metrics import mean_squared_error, r2_score
print(np.sqrt(mean_squared_error(test["target"], preds)))
print(r2_score(test["target"], preds))
# ========== output ==========
# 62.63916269284634
# 0.5240617310863488平均二乗誤差の平方根とR2スコアを計算しました。
R2が0.52なのでそこそこの精度です。
まとめ
今回はTensorFlowでモデルを作る方法を解説しました。
TensorFlowならTPUで高速に学習できるので、普段Pytorchを使う方でも勉強しておくと良いですね。


コメント