

今回はTensorFlow(Keras)でEfficientNetを使い、画像分類をする方法を解説します。
モデル作成の基礎的なことはこちらの記事に書いています。
今回の内容が難しくてできるだけ簡単な画像分類をしてみたい人は、以下の記事をどうぞ。
>>手書き数字の画像分類モデルを作る方法
データセット
都合よく画像データを持っている人も少ないと思いますので、
tensorflowに入っている画像を使いましょう。
import tensorflow as tf
(X_train, y_train), (X_test, y_test) = tf.keras.datasets.cifar10.load_data()
print(X_train.shape, X_test.shape)
print(y_train.shape, y_test.shape)
# ========== output ==========
# (50000, 32, 32, 3) (10000, 32, 32, 3)
# (50000, 1) (10000, 1)cifar10をダウンロードしましょう。
カエルやネコなど10種類に分けられる画像が入っています。
trainが学習用データ、testが検証用データです。
import matplotlib.pyplot as plt
plt.imshow(X_train[0])
plt.title(y_train.reshape(-1)[0])
plt.show()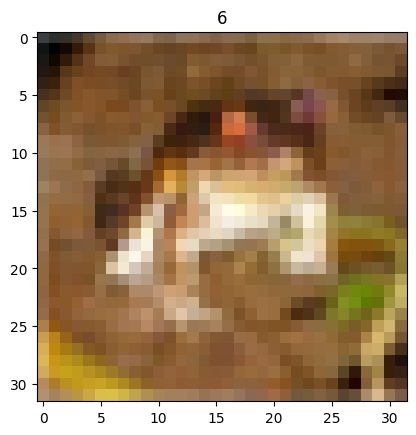
1枚目の画像を表示しました。カエルですね。
ラベルは6番です。
plt.figure()
for i in range(9):
plt.subplot(3, 3, i + 1)
plt.imshow(X_train[i])
plt.title(y_train.reshape(-1)[i])
plt.tight_layout()
plt.show()
このように写真の種類によってバラバラなラベルが与えられています。
例えば1は車で6がカエルです。ラベルは合計で10種類あります。
ようするに、画像からラベルの数値を当てられたら成功です。
Dataset
from_tensor_slicesにデータを渡すとデータセットが作れます。
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
test_dataset = tf.data.Dataset.from_tensor_slices((X_test, y_test))
# バッチサイズ
train_dataset = train_dataset.batch(32)
test_dataset = test_dataset.batch(32)
# シャッフル
train_dataset = train_dataset.shuffle(1024 * 50)
# 1つ目のバッチを確認
batch = next(iter(train_dataset))
print(batch[0].shape)
print(batch[1].shape)
# ========== output ==========
# (32, 32, 32, 3)
# (32, 1)画像データを1度にすべて読み込むとメモリがパンクするので、バッチサイズごとに小出しします。
今回は32枚ごとです。
学習用データはシャッフルしておきましょう。
()に入れる値は、合計データ数以上にしておけば無難です。
1バッチだけ取り出してみると、確かに32個のデータが入っていますね。
(32, 32, 32, 3) = (バッチサイズ, 縦, 横, RGB)
ラベルは各画像に1つなので、データサイズは(バッチサイズ, 1)です。
モデル作成
モデル定義の細かい仕様はこちらを参考にしてください。
今回はモデルを作る方法を2つ紹介しますので、お好きな方を使ってください。
keras.applications
import tensorflow.keras.layers as L
import tensorflow.keras.models as M
def get_model(image_size, num_classes):
# 画像を受け取る層
inputs = L.Input(shape = image_size)
# EfficientNetB0を作成
x = tf.keras.applications.efficientnet.EfficientNetB0(include_top = False)(inputs)
# 1次元に変換する層
x = L.Flatten()(x)
# 最終出力層
outputs = L.Dense(units = num_classes, activation = "softmax")(x)
# 定義した層を使ってモデル作成
model = M.Model(inputs = inputs, outputs = outputs)
# 最適化手法と損失関数を定義
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate = 5e-5),
loss = "sparse_categorical_crossentropy"
)
return model
# モデルの呼び出し
tf.keras.backend.clear_session()
model = get_model(X_train.shape[-3:], 10)
model.summary()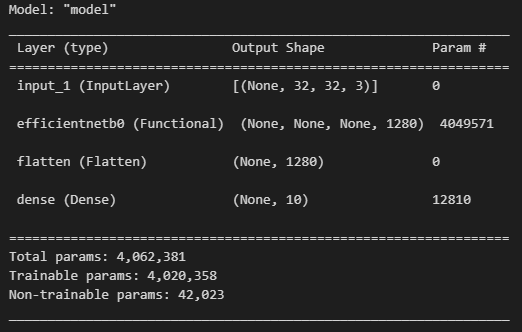
モデルはEfficientNetB0を使います。
これは大規模なデータセットで事前学習されたものなので、最初からそこそこ精度が良いです。
それに加えて今回のデータで転移学習をさせます。
出力をFlattenで1次元に変換してからDenseでラベル数に合わせましょう。
損失関数をsparse_categorical_crossentropyにするとOhe-Hot変換しなくて済みます。
最初のinput_sizeは(縦, 横, RGB)、つまり(32, 32, 3)を入れています。
tfimm
#!pip install -q tfimm timm # <- installしていない場合は実行
import tfimm
[m for m in tfimm.list_models() if "efficientnet" in m]
# ========== output ==========
# ['efficientnet_b0',
# 'efficientnet_b0_ap',
# 'efficientnet_b0_ns',
# 'efficientnet_b1',
# ...tfimmを使うとpytorchのように様々なモデルを扱うことができます。
上記のコードは名前に”efficientnet”が入っているモデルを表示しています。
import tensorflow.keras.layers as L
import tensorflow.keras.models as M
def get_model(image_size, num_classes):
inputs = L.Input(shape = image_size)
# EfficientNetB0を作成
x = tfimm.create_model("efficientnet_b0", pretrained = True, nb_classes = 0)(inputs)
x = L.Flatten()(x)
outputs = L.Dense(units = num_classes, activation = "softmax")(x)
model = M.Model(inputs = inputs, outputs = outputs)
model.compile(
optimizer = tf.keras.optimizers.Adam(learning_rate = 5e-5),
loss = "sparse_categorical_crossentropy"
)
return model
# モデルの呼び出し
tf.keras.backend.clear_session()
model = get_model(X_train.shape[-3:], 10)
model.summary()このようにEfficientNetB0の部分をtfimmのモデルに変えましょう。
以上、どちらの方法で使ってモデルを作ってもOKです。
学習と検証
まずGoogle Colaboratoryを使っている人はGPUをONにしましょう。
”ノートブックの設定”からGPU(T4)に設定すればOKです。
CPUのままでも構いませんが、計算に時間がかかります。

以下のコードを実行すると学習と検証を行います。
checkpoint = tf.keras.callbacks.ModelCheckpoint(
"best_weight.h5", # ファイル名
monitor = "val_loss", # 参照するloss
mode = "min", # monitorが最小のときに保存
save_best_only = True,
save_weights_only = True
)
history = model.fit(
train_dataset,
validation_data = test_dataset,
epochs = 10,
callbacks = [checkpoint]
)ModelCheckpointは最も結果が良かった時点でのモデルを保存するものです。
train_datasetが学習時のデータセットで、validation_dataが検証時のデータセットです。
epochsの数だけ学習と検証を繰り返します。
plt.plot(history.history["loss"], label = "train")
plt.plot(history.history["val_loss"], label = "valid")
plt.legend()
plt.show()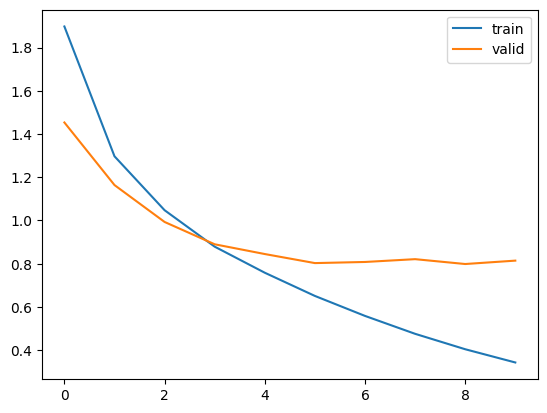
結果はこのとおりです。徐々にlossが下がっていれば成功です。
予測
# モデルの読み込み
model.load_weights("best_weight.h5")
preds = model.predict(test_dataset)
print(preds[0])
print(y_test[0])
# ========== output ==========
# [2.6435443e-04 8.1145071e-04 1.2745401e-04 9.4737655e-01 4.0097401e-04
# 4.4634677e-02 7.0899853e-04 1.0307332e-03 3.5173900e-03 1.1272756e-03]
# [3]保存した最も精度の良い状態を読み込み、predictで予測しましょう。
各列がそれぞれのラベルに該当する確率になっています。
よく見ると4番目の確率が0.94(0, 1, 2, 3, …と数える)なので、ラベル3の確率が最大になっています。
pred_labels = preds.argmax(axis = 1)
print(pred_labels[:5])
print(y_test[:5].reshape(-1))
# ========== output ==========
# [3 8 8 8 6]
# [3 8 8 0 6]argmaxで確立が最も大きい列番号を予測ラベルとしました。
だいたいあっていそうですね。
正解率を計算してみましょう。
from sklearn.metrics import accuracy_score
print(accuracy_score(pred_labels, y_test.reshape(-1)))
# ========== output ==========
# 0.7213正解率は72.1%でした。
これでモデルの作成は完了しました。
以降の内容は精度アップの方法なので、興味ある人は読んでみてください。
Data Augmentation
Data Augmentationとは、画像を反転したり色を変えたりして加工しましょうということです。
例えば以下のコードで上下左右に反転してみましょう。
def augmentation(image, label):
image = tf.image.random_flip_left_right(image) # 左右反転
image = tf.image.random_flip_up_down(image) # 上下反転
return image, label
image = X_train[4]
plt.figure()
for i in range(9):
image = augmentation(image, _)[0]
plt.subplot(3, 3, i + 1)
plt.imshow(image)
plt.show()“random_flip_left_right”が左右、”random_flip_up_down”が上下に50%の確立で反転させます。
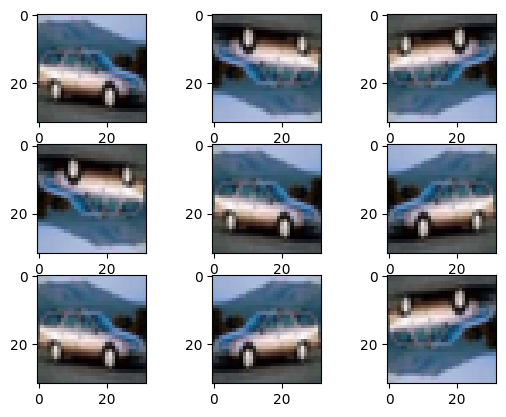
こんな感じで車の画像を反転できます。
しかし、どの向きをしていても車であることには変わらないので、
すべてのパターンを学習させることで表現力を上げることができます。
train_dataset = tf.data.Dataset.from_tensor_slices((X_train, y_train))
train_dataset = train_dataset.batch(32)
train_dataset = train_dataset.shuffle(1024 * 50)
train_dataset = train_dataset.map(augmentation)データセットを作り直しました。”map”で画像変換を適用させています。
あとは同じように学習と検証を繰り返しましょう。
# モデルリセット
tf.keras.backend.clear_session()
model = get_model(X_train.shape[-3:], 10)
checkpoint = tf.keras.callbacks.ModelCheckpoint(
"best_weight.h5", # ファイル名
monitor = "val_loss", # 参照するloss
mode = "min", # monitorが最小のときに保存
save_best_only = True,
save_weights_only = True
)
history = model.fit(
train_dataset,
validation_data = test_dataset,
epochs = 15,
callbacks = [checkpoint]
)
plt.plot(history.history["loss"], label = "train")
plt.plot(history.history["val_loss"], label = "test")
plt.legend()
plt.show()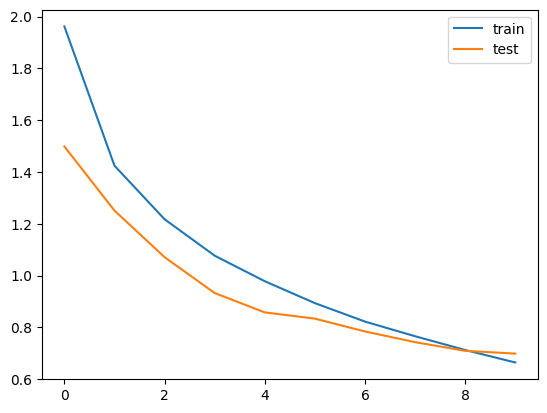
モデルを再度呼び出して学習させましょう。
さっきよりもlossが下がっていますね。
# モデルの読み込み
model.load_weights("best_weight.h5")
preds = model.predict(test_dataset)
pred_labels = preds.argmax(axis = 1)
print(accuracy_score(pred_labels, y_test.reshape(-1)))
# ========== output ==========
# 0.758正解率も75.8%まで伸びました。
他にも色を変えたり画像を回転させたりと、様々な変換方法があります。
まとめ
今回はTensorFlow(Keras)で画像分類モデルを作成しました。
モデル作成自体はEfficientNetを使うだけなので簡単ですね。

コメント