

機械学習をやってみたいけど、
いったい何から始めたらいいのかわからない。。。
という人は、Titanicデータから始めてみましょう。
今回はSeabornに入っているTitanicデータを使って、機械学習を始める方法について解説します。
Pythonを実行する環境がない方は、Google Colaboratoryを使ってみてください。
>>Google Colaboratoryを使う方法
データ準備
import seaborn as sns
data = sns.load_dataset("titanic")
print(data.shape)
data.head()
# ========== outputs ==========
# (891, 15)
seabornからデータを取り出します。
“load_dataset”に”titanic”と入れましょう。
データのサイズは891行です。”survived”が1なら生存したことを意味します。
なので、それ以外の列から“survived”が0,1どちらかを予測するモデルを作成しましょう。
前処理
カテゴリデータと数値データ
このデータを見ると、”pclass”や”age”は数値で、”sex”や”embarked”は文字になっています。
機械学習モデルは数値しか受け取れませんので、文字データを数値に変換しましょう。
from sklearn.preprocessing import LabelEncoder
lbl = LabelEncoder()
for col in ["sex", "embarked", "adult_male", "class", "who", "deck", "alone"]:
data[col] = lbl.fit_transform(data[col])
data.head()
“LabelEncoder”で文字を数値に変換しました。
例えば”sex”列は、”male”を0、”female”を1として表しています。
“embark_town”は”embarked”と中身がかぶっているので、今回は無視します。
“alive”は”survived”と同じなので、これも無視しましょう。
cat_cols = [c for c in data.columns if data[c].dtype == "object"]
num_cols = [c for c in data.columns if data[c].dtype != "object"]
print(cat_cols)
print(num_cols)
# ========== outputs ==========
# ['embark_town', 'alive']
# ['survived', 'pclass', 'sex', 'age', 'sibsp', 'parch',
# 'fare', 'embarked', 'class', 'who', 'adult_male', 'deck', 'alone']“cat_cols”がカテゴリデータ、”num_cols”が数値データの列名です。
欠損値処理
data.isnull().sum() / len(data)
# ========== outputs ==========
# survived 0.000000
# pclass 0.000000
# sex 0.000000
# age 0.198653
# ...isnullでデータが入力されているかを確認できます。”age”では約20%データが欠損してますね。
今回は決定木系のLightGBMを使いたいので、実は欠損値があっても大丈夫です。
ですが、”欠損していること”をモデルに伝えるためにダミーで-99を入れておきましょう。
data["age"].fillna(-99, inplace = True)
data["age"].isnull().sum()
# ========== outputs ==========
# 0これでOKです。
データ分析がうまくできるなら、うまいこと年齢を仮定して埋めておくのも良いですね。
学習データと検証データに分割
from sklearn.model_selection import train_test_split
train, test = train_test_split(
data, test_size = 0.1, stratify = data["survived"], random_state = 0
)
print(train.shape, test.shape)
# ========== outputs ==========
# (801, 15) (90, 15)分割したあとのサイズを見ると9:1になっていればOKです。
【関連記事】データ分割でよく使う手法
学習と検証
特徴量と目的変数に分割
feat_cols = [c for c in num_cols if c != "survived"]
X_train = train[feat_cols]
y_train = train["survived"]
X_test = test[feat_cols]
y_test = test["survived"]
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)
# ========== outputs ==========
# (801, 12) (801,)
# (90, 12) (90,)モデルに入れる特徴量を”feat_cols”として定義しました。
数値データから予測したい”surveved”を除去しています。
学習
import lightgbm as lgbm
params = {"objective": "binary", "learning_rate": 5e-2, "verbosity": -1}
train_set = lgbm.Dataset(X_train, y_train)
test_set = lgbm.Dataset(X_test, y_test)
history = {}
model = lgbm.train(
params = params,
train_set = train_set,
valid_sets = [train_set, test_set],
callbacks = [lgbm.callback.record_evaluation(history)],
)このコードで学習できます。
LightGBMの使い方について、詳しくはこちらの記事で解説しています。
import matplotlib.pyplot as plt
plt.plot(history["training"]["binary_logloss"], label = "train")
plt.plot(history["valid_1"]["binary_logloss"], label = "test")
plt.legend()
plt.show()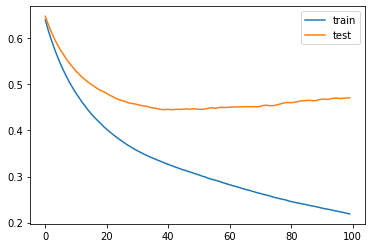
こんな感じで徐々に誤差(logloss)が下がっていればOKです。
黄色の検証データで最も誤差の小さい、40回目くらいのモデルが保存されます。
予測と精度確認
preds = model.predict(X_test)
print(preds.shape)
print(preds[:5])
print(y_test.values[:5])
# ========== outputs ==========
# (90,)
# [0.03185021 0.72064654 0.14265358 0.49432573 0.07159848]
# [0 0 0 1 0]predictで予測できます。
確率で出力されるので、閾値を設定するなどして01に変換する必要があります。
from sklearn.metrics import accuracy_score, roc_auc_score
acc = accuracy_score(y_test, preds > 0.5)
auc = roc_auc_score(y_test, preds)
print(acc)
print(auc)
# ========== outputs ==========
# 0.8111111111111111
# 0.8524675324675324正解率が81.1%で、AUCが0.852でした。
例えばラベル0のデータが多い場合、全て0と予測する適当なモデルでも正解率が良くなります。
なので正解率だけでなく、AUCも見ておきましょう。
特徴量重要度
lgbm.plot_importance(model, importance_type = "gain", height = 0.8)
plt.show()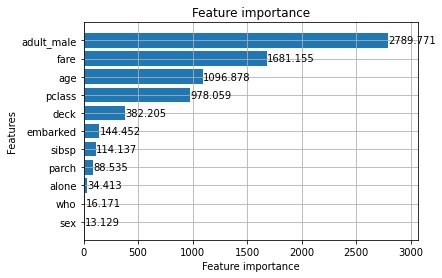
LightGBMなら特徴量の重要度を見ることができます。
成人男性であるかどうかで、生存率が左右されているみたいですね。
まとめ
今回はSeabornに入っているTitanicデータで機械学習モデルを作る方法を解説しました。
初心者はみな触るデータだと思いますので、ぜひ第一歩として挑戦してみてください。


コメント